
Blog
5 Best Practices for Effective Insurance Underwriting
By: Stefan Gergely -
30 January 2026


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

Key Takeaways:
Picture this: your mid-sized firm approves a policy for a multi-location manufacturing company. On paper, everything looks low-risk.
But within months, one location experiences a catastrophic fire, another suffers equipment failure, and claims spiral far beyond expectations.
What went wrong?
That’s the risk you take when you rely on conventional underwriting methods, which heavily lean on self-reported information and fragmented datasets.
You miss out on the bigger picture, and high-risk exposures remain hidden until disaster strikes.
Effective underwriting today demands more than intuition and basic forms. It calls for complete, validated data, location-level insight, centralized platforms, automation, and AI-driven analysis.
This article dives deep into the five best practices to transform underwriting from reactive guesswork into a precise, proactive, and profitable process.
Let’s start with the most critical building block of modern underwriting—data completeness.
Incomplete or outdated insurance data creates significant underwriting blind spots, including misclassification, incorrect pricing, and coverage gaps.
While advanced tools and models can enhance underwriting, the accuracy of every decision still hinges on the quality of the underlying data.
According to Capgemini Research Institute, weak data sources contribute to 77% of insurers experiencing incomplete risk evaluation.
Additionally, 73% of insurers report limited pricing accuracy due to data limitations, which directly impacts accurate underwriting and appropriate coverage decisions.
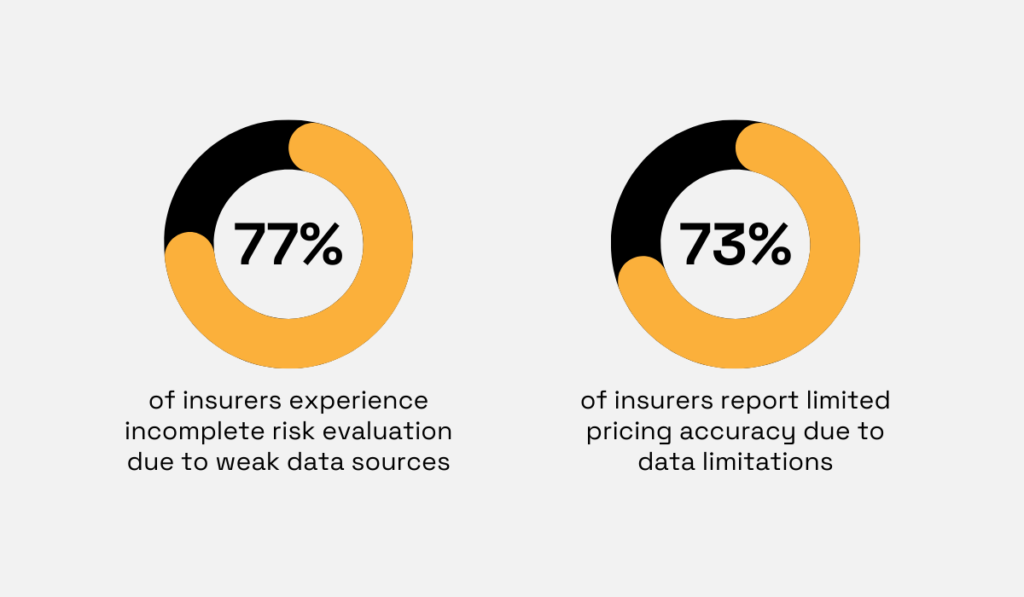
Illustration: Veridion / Data: Capgemini
In commercial insurance, where risk profiles can vary significantly across locations, operations, and time, relying on incomplete or outdated information introduces material risk into pricing, coverage, and portfolio performance.
This underscores the importance of accurate, up-to-date, consistent, complete, and reliable data in laying a solid foundation for effective underwriting.
Joanne Butler, former head of Product Marketing and Pre-Sales at Charles Taylor, a provider of insurance services and technology solutions, agrees:

Illustration: Veridion / Quote: Charles Taylor
For example, a commercial property insurer who only relies on declared occupancy type, such as “warehouse” or “light manufacturing,” and basic property attributes, underestimates the risk on paper.
The blind spot is that the actual on-site operations may differ from the declared use.
But when underwriting includes comprehensive data, the insurer sees:
In this case, patterns and behavior that wouldn’t appear in incomplete datasets are now visible, improving risk selection and portfolio performance.
That’s why it’s important not to rely solely on applicant-provided information.
The conventional procedure involves either soliciting businesses to voluntarily disclose risk factors or conducting manual research.
While submissions and broker disclosures are essential starting points, they often reflect how a business describes itself rather than how it actually operates.
Businesses evolve when they add or repurpose locations, shift activities, or change financial conditions, yet applications may lag behind reality.
Without independent validation, underwriters risk assessing an incomplete or inaccurate version of the exposure.
This is why validating business activities, locations, and financials using independent data sources is critical.
Veridion addresses this challenge by providing verified, standardized business data that gives your underwriters a clearer view of real-world operations.
As an AI-powered business intelligence tool, it has multilingual machine learning models that extract critical business details for over 130 million businesses across 240 countries.
With a simple input, such as a business commercial name, legal name, and an address, you can access over 320 data points for any business worldwide with minimal effort, ensuring unparalleled coverage and data availability.
Here’s an example of a segment of a company profile:
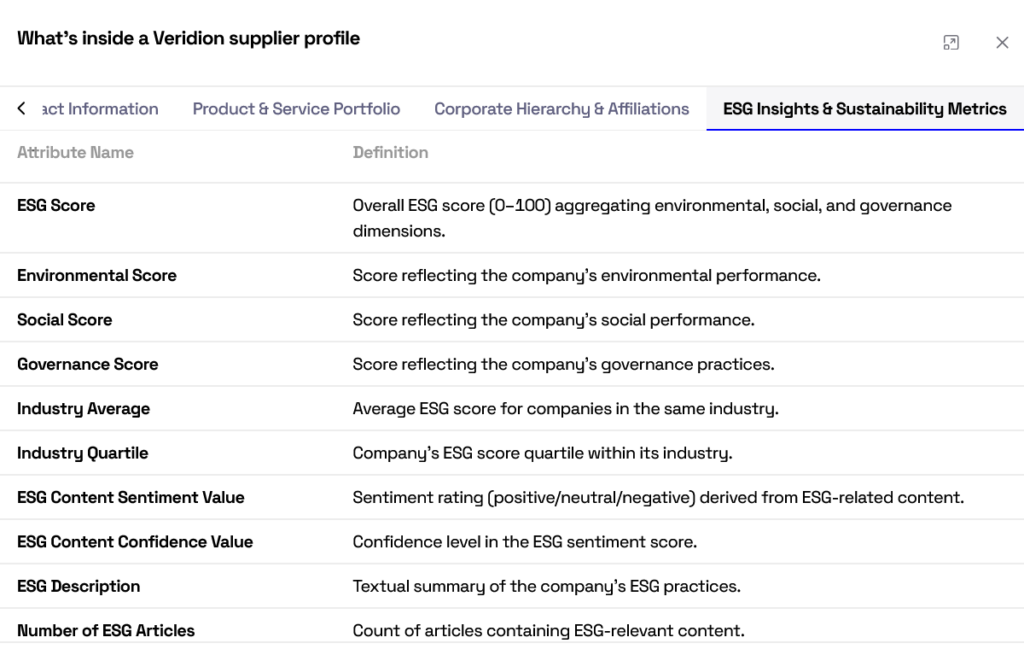
Source: Veridion
The best part?
You can leverage our data and tools for multiple use cases, outlined in the table below:
| Use Case | Veridion Application |
|---|---|
| Quoting & Pricing (Underwriting) | Automates classification and improves the underwriting triage process, assigns limits and coverage, and validates applicant data |
| Book & Risk Management (Underwriting) | Reveals new business activities at a site, operational expansion or contraction, and changes in site usage |
| Claimant Validation (Claims) | Proactively validates self-reported information about claimant businesses and identifies inaccuracies to eliminate fraudulent claims |
| Pricing & Loss Ratio Modelling (Actuarial Modelling) | Applies new variables such as locations, risks, business activities, and others to provide more accurate policy coverage and reduce risk exposures |
| Prospecting & Lead Prioritization (Sales & Distribution) | Streamlines lead identification by location, segmentation, and business characteristics, increasing the probability of conversions and discovering new market opportunities |
Ultimately, improving data completeness directly improves risk selection and portfolio performance.
Better data leads to more accurate classification, more defensible pricing, and fewer surprises at claim time.
While company-level data provides a useful starting point, it often obscures location-level conditions, hazards, and concentrations that ultimately drive loss severity.
Many material risks in commercial insurance are revealed only after underwriting is performed at the individual location level.
Property damage, business interruptions, liability events, and catastrophe losses all occur at physical sites, not at abstract entity levels.
When risk is assessed only at the company level, extreme exposures are often averaged out.
High-severity, low-frequency risks, such as a manufacturing plant in a wildfire zone or a warehouse holding most of the insured value, can represent a disproportionate share of loss potential, yet remain hidden among lower-risk locations.
Assessing risk only at the company level leads to:
In such cases, hidden risks are only revealed after a major claim.
Mark Breading, a senior partner at Resource Pro, underscores this:

Illustration: Veridion / Quote: Insurance Thought Leadership
Two locations owned by the same company can have radically different risk profiles based on geographic exposure, building characteristics, surrounding tenants, and access to emergency services.
Without location-level insight, underwriters may overlook changes in risk that materially alter exposure.
This remains true for customers who relocate.
Take this case study, for example:

Source: Veridion
Assessing risk at the individual location level enables underwriters to align pricing, limits, deductibles, and coverage terms with actual exposure.
With site-specific insight, insurers can:
Consider, for instance, the location intelligence analysis of catastrophic wildfire losses in California.
A top U.S. insurer found that, of 100 properties that suffered over $100 million in claims, only 3% had previously been identified as high risk using zip-code-level data.
With precise location-level data, 50% to 75% of the properties would have been flagged as high risk.
Ultimately, location-level risk analysis replaces assumptions with evidence.
Let’s say you’re underwriting a multi-location manufacturer.
In a fragmented setup, site details arrive via broker emails, spreadsheets, and attachments.
One legacy system lists a warehouse as low-risk storage, while another classifies it as light manufacturing.
At renewal, the underwriter relies on outdated records and prices the risk accordingly, only for a claim to reveal a materially different exposure.
Simply put, data silos block the bigger picture, compelling underwriters and brokers to work with outdated and incomplete data.
Now, imagine the operational strain of applying this process to thousands of submissions.
Insurers with fragmented data experience slower submissions, more manual tasks, and errors that gradually weaken trust between parties.
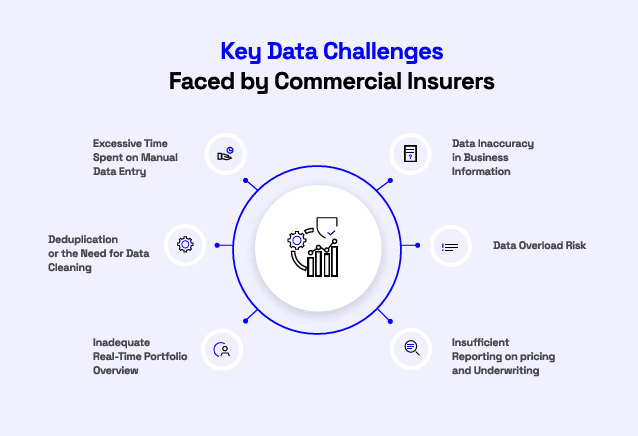
Source: Veridion
While many insurance companies are drowning in big data, a Deloitte survey found that 53% of insurers lack a 360-degree view of their policyholders due to legacy systems and fragmented data sources.
This shows that even among digitally aware insurers, a majority still lack end-to-end customer visibility.
Now imagine a centralized data platform where each account is anchored to a single dataset.
Location use, construction type, and exposure values are updated once and reflected everywhere.
Any material change triggers visibility across underwriting, portfolio management, and reinsurance teams.
Decisions are aligned because everyone is making them based on the same information, and effective insurance underwriting hinges on unified data.
Phil Ratcliff, a global insurance leader at Ensono, an expert technology adviser and managed service provider, emphasizes that many insurers stay stuck in maturity stages due to outdated mindsets.
A strong data foundation helps you forecast risk with high accuracy, using real-time insights, not historical snapshots.

Illustration: Veridion / Quote: Insurance Thought Leadership
Centralized data platforms eliminate misalignment and second-guessing.
Underwriters, actuaries, portfolio managers, and risk engineers gain shared visibility into the same data.
Decision logic becomes easier to trace, defend, and refine over time.
Simply put, these platforms transform your underwriting into a repeatable, transparent, collaborative, and defensible process.
Many insurers still devote excessive time to repetitive, routine tasks that deliver little underwriting or strategic value.
For your company, this could be data ingestion, initial screening, or documentation.
For others, it’s bank verification, accumulation checks, and responding to repetitive inquiries.
While the tasks vary, the impact is the same.
They divert underwriters from high-value work that directly drives risk quality, pricing accuracy, and portfolio performance.
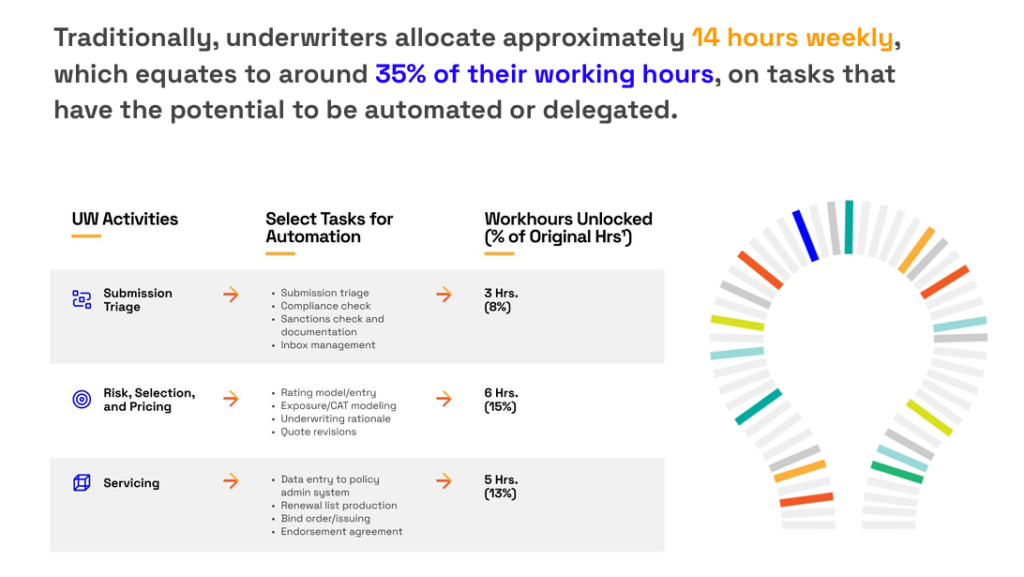
Source: Veridion
Let’s say you’re onboarding new SME applicants manually.
In that case, underwriters would have to verify company identities, cross-check ownership details, reconcile multiple data sources, and perform initial risk screening, then repeat the same steps for similar entities.
Freeing them from these routine responsibilities directly impacts their ability to focus on complex risk evaluation and judgment-based decisions.
With more bandwidth, underwriters can analyze nuanced risk factors, assess emerging threats, and make informed decisions that influence the profitability and competitiveness of the insurance portfolio.
Processes that once took hours or days can now be completed in minutes, allowing you to respond faster to clients and market changes.
Let’s go back to our SME example.
By integrating Veridion Match & Enrich API, you can automatically match each applicant to a verified business profile and enrich it with standardized attributes, such as:
The system flags anomalies or missing information upfront, allowing underwriters to immediately focus on complex risk considerations, unusual exposure profiles, or emerging threats.
In other words, manual processes that would take 60-90 minutes per entity are reduced to around 1.5 seconds.
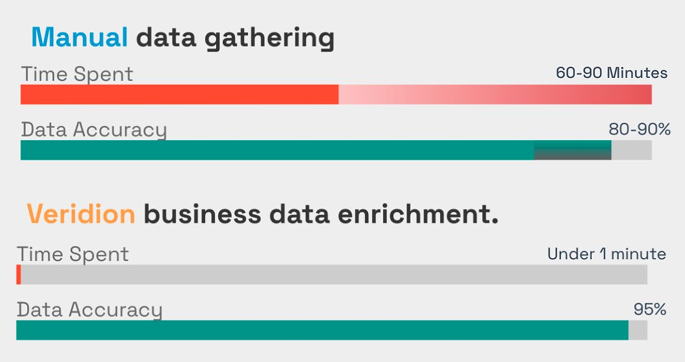
Source: Veridion
Ultimately, the goal of automation isn’t to replace underwriters.
It is to augment their expertise.
This shift elevates the overall quality of underwriting decisions by ensuring that human judgment is applied where it matters most.
Insurance risk analysis and underwriting involve large, complex datasets.
The problem?
Traditional manual analysis methods often fall short at identifying patterns, anomalies, and emerging risks.
They struggle to keep up with the complexity and volume of data used by modern insurers.
This is where AI truly shines.
It augments human expertise by uncovering insights that are difficult or impossible to detect through manual analysis alone.
AI helps underwriters move beyond surface-level indicators and toward deeper, more proactive risk understanding.
By analyzing large amounts of structured and unstructured data, such as loss histories, industry data, submission documents, geospatial information, and external signals, AI models can reveal correlations and deviations that may not be immediately obvious to the human eye.
Traditional risk analysis is grounded in historical data and broad statistical assumptions.
AI-driven models enrich this approach with real-time inputs from IoT devices, social media, and other external sources, revealing risk signals that often emerge before severe claims occur.
Chairman and CEO Peter Zaffino is driving AIG’s transformation through AI-powered innovation:

Illustration: Veridion / Quote: Time
Machine learning models further enhance risk analysis by supporting risk segmentation, loss prediction, and early warning signals.
Advanced models can group risks more precisely based on shared characteristics, enabling more consistent underwriting decisions across portfolios.
Predictive models also estimate loss likelihood and severity by learning historical outcomes, while early warning systems detect changes in exposure or behavior that indicate rising risk, often before losses materialize.
Together, these capabilities allow insurers to act earlier and with greater confidence, rather than reacting after losses occur.
And the shift from reactive to proactive risk management is already underway across the industry.
According to Ernst & Young, insurers are already investing heavily in predictive analytics and AI-enabled risk analysis.
74% of firms have already identified it as a key area for underwriting and claim functions, with 78% of commercial P&C firms leading the adoption.

Illustration: Veridion / Data: Ernst & Young
So, don’t be left behind. Stay ahead of the curve.
Effective AI-driven risk analysis depends on understanding model inputs, assumptions, and limitations, and AI outputs are only as reliable as the data and design behind them.
Underwriters, therefore, must understand:
Used responsibly, AI doesn’t replace underwriting expertise. It enhances it.
By providing clearer signals and reducing analytical noise, it empowers underwriters to apply their judgment more strategically and consistently.
The future of underwriting belongs to insurers who act on insight, not assumption.
Often, the real risk isn’t what’s on paper. It’s what goes unseen.
The greatest edge in underwriting comes from asking smarter questions, validating assumptions, and understanding the story behind every number.
The most successful insurance firms are those that anticipate hidden risks, rather than wait to react.
So remember: data-driven, proactive underwriting turns uncertainty into opportunity, and hidden exposures are only as dangerous as the insights you lack.