
Blog
Best Practices for Data Ownership
By: Auras Tanase -
07 April 2026


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

Key Takeaways:
Data ownership, a key component of data governance, plays a pretty big role in ensuring the accuracy, reliability, and security of your data.
But are your teams following the right practices to maintain strong data ownership?
Are they even aware of what those practices entail?
If the answer is no, don’t panic just yet. There’s work to be done, sure, but this article will guide you through it.
Below, we outline five data ownership best practices to help you strengthen your governance framework and unlock the full potential of your data.
Every key data domain needs a formally assigned owner and steward who are accountable for data accuracy, definitions, access approvals, and more.
Clearly defined roles are one of the most important foundations of strong data ownership and, ultimately, effective governance.
A survey by the Enterprise Data Strategy Board confirms this, showing most data leaders agree that the best way to drive governance adoption is by assigning dedicated data owners and stewards.
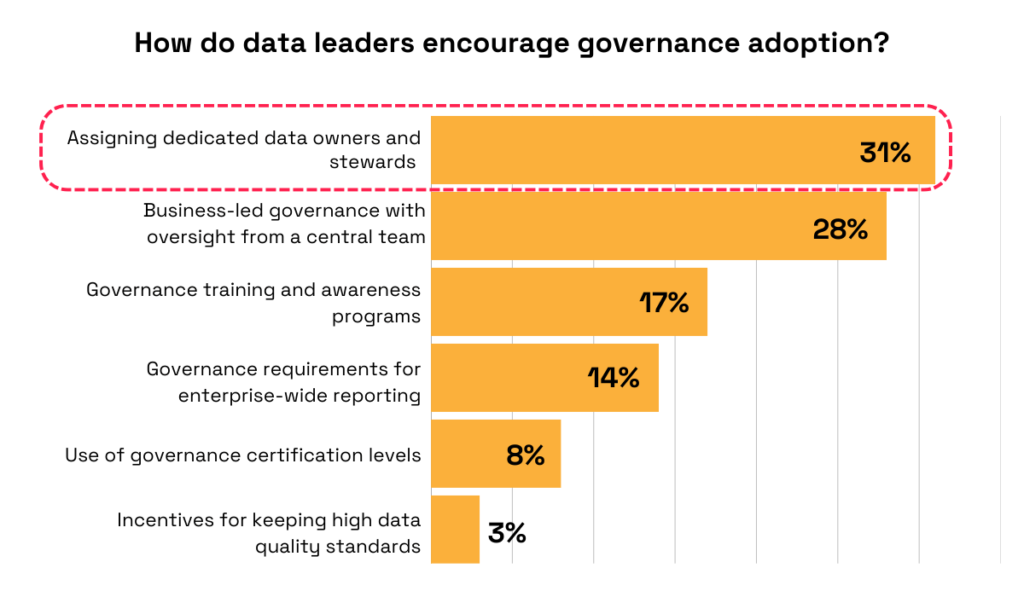
Illustration: Veridion / Data: Enterprise Data Strategy Board
That’s because, without clearly defined roles, nobody truly knows who is in charge, and responsibility is often just assumed.
And this lack of accountability can only lead to poor decisions and a decline in data quality.
One Reddit user experienced this problem firsthand:
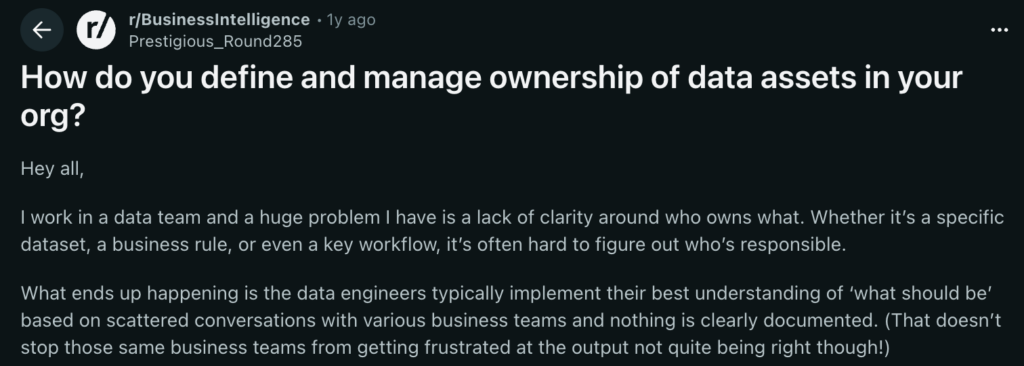
Source: Reddit
So, to eliminate this kind of confusion and ambiguity, you must establish and then document clear ownership roles.
The three most common are:
| Data Owner | Has ultimate authority over data assets. Typically, a senior executive or department head, the data owner is responsible for defining policies, access controls, and compliance requirements. |
| Data Steward | Ensures data policies are enforced so that data stays accurate, consistent, and aligned with governance rules. Works closely with data owners and data custodians. |
| Data Custodian | Responsible for the technical aspects of data storage, security, and infrastructure. These duties usually fall within the IT teams or database administrators. |
These roles should be appointed for each major data domain, such as financial data, supply chain data, or employee records, and then formalized using a RACI matrix.
RACI stands for Responsible, Accountable, Consulted, and Informed, and represents a framework used to clarify levels of responsibility within a process, or in this case, across the data lifecycle.
Here’s an example of what that might look like, provided by Joshua Depiver, Data Governance Manager at NextEnergy Group, a global renewables group focused on solar-plus infrastructure:
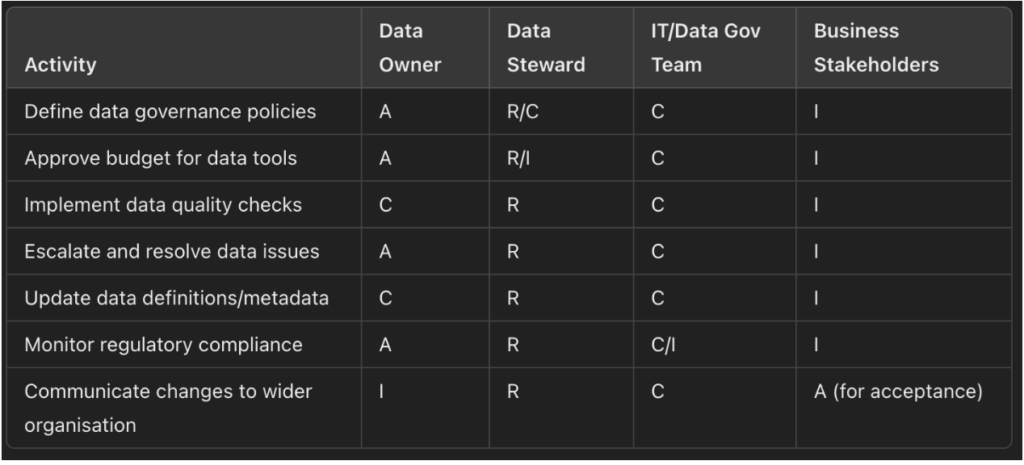
Source: LinkedIn
With a clearly defined RACI model in place, everyone understands who is responsible for each task across the entire data lifecycle.
In the end, implementing this one single practice can make all the difference in your data ownership and governance effectiveness.
Defining objective, measurable, and enforceable criteria that determine whether data is fit for its intended purpose is non-negotiable, too.
This ensures everyone understands exactly what “good” looks like, thereby reducing errors and strengthening overall data reliability.
After all, isn’t high-quality, trustworthy data that drives better decisions the ultimate goal of any organization?
Maria C. Villar, Managing Partner at Business Data Leadership, a company promoting effective data management through training, writing, and consulting, puts it perfectly:

Illustration: Veridion / Quote: Technology Magazine
She compares reliable data to electricity powering every part of a company, explaining that the more confidence you have in it, the faster and better your decisions become.
Formal data quality standards give you this confidence.
When establishing these standards, ensure they address all key dimensions of data quality:
| Data accuracy | Data reflects reality without significant errors or inconsistencies |
| Data completeness | Data sets contain all relevant information, without critical gaps |
| Data consistency | Data doesn’t contradict itself or other trusted sources |
| Data timeliness | Data is up to date and relevant to the timeframe of analysis |
| Data validity | Data conforms to required formats, types, and acceptable value ranges |
| Data uniqueness | Data does not contain unwanted duplicates |
With these dimensions in mind, you can design clear quality metrics for each high-impact data domain.
Some examples include required fields, minimum completeness thresholds, refresh cadence, acceptable error rates, and review frequency.
You can also draw inspiration from UNICEF’s data quality framework.
UNICEF collects, analyzes, and publishes a wide range of global datasets, making strong data ownership and governance very important for their goals and mission.
Their framework is, therefore, quite detailed, defining what good data use looks like, clarifying the elements of high-quality data, and outlining the data evaluation processes.
Below, you’ll find a small portion of the document:
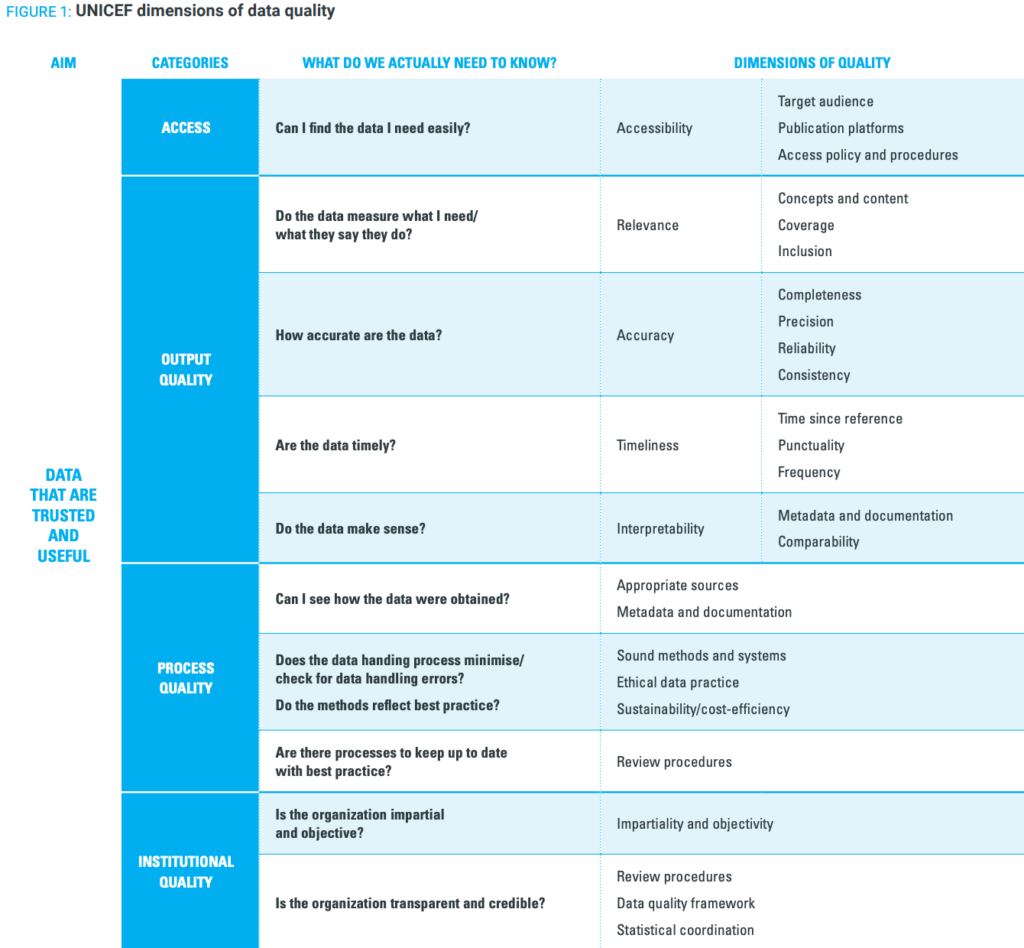
Source: UNICEF
As you can see, they use the same quality dimensions we described above, but have included additional criteria tailored to their specific context.
You can do the same. No need to feel limited to just those six dimensions.
Sure, they can be a great starting point, but your organization’s unique needs, goals, and operating environment should always be the number one priority.
Part of your data quality framework should also include periodic reviews of data accuracy using external intelligence platforms.
This is the icing on the data quality controls cake that reinforces data accuracy, completeness, timeliness, and uniqueness.
Research from Validity reveals why supplementing internal records through data enrichment is so important.
A lot of companies report that their data is inaccurate, and, even more concerningly, many admit that employees sometimes fabricate data to tell the story they want decision-makers to hear.
In other words, your internal records may not be as reliable as you think.
Furthermore, the same research shows that companies estimate losing more than 10% of annual revenue due to poor-quality CRM data.
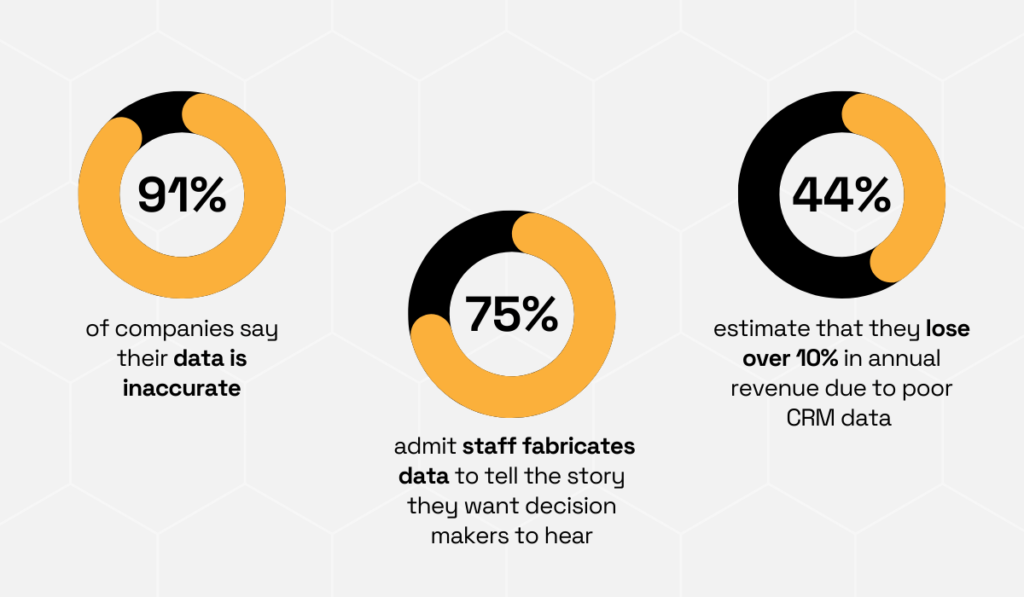
Illustration: Veridion / Data: Validity
And that’s just CRM. Imagine the inefficiencies and losses that may exist across your other systems.
That’s why external AI-powered business intelligence platforms like Veridion can be powerful allies, shielding you against poor data, flawed decisions, and lost profits.
Veridion continuously updates its vast database, which currently consists of more than 130 million companies across the world.
Each business profile is verified through a rigorous validation process and includes hundreds of attributes, such as industry classifications, location intelligence, ESG performance, and so much more.
With Veridion’s enrichment service, you get to integrate this intelligence directly into your existing systems.
Learn more about it here:
Source: Veridion on YouTube
The platform supplements your current data, assesses potential risks, removes duplicates, and updates outdated records, providing you with a richer, more reliable dataset.
Here’s what Veridion’s data enrichment entails:
| Normalize | Identify duplicates, standardize records, and roll companies up to parent entities |
| Enrich and Update | Enhance each record with updated attributes such as contact information, locations, company names, products and services, sustainability data, tax IDs, and more |
| Classify | Categorize companies by industry, geography, diversity, ownership, and other relevant classifications |
| Validate and Monitor | Verify records for accuracy and continuously monitor them for changes |
The world of business data is becoming more complex, seemingly by the minute. Expecting your data owners to handle it all manually is unrealistic.
But with tools like Veridion, you can stay on top of every entity in your records with minimal effort, accessing the freshest insights, correcting errors proactively, and enriching your data for a complete 360-degree view.
Data ownership champions establish strict rules for data access based on role, business need, and data sensitivity.
As a result, they are more successful at reducing the risk of non-compliance and compromised data integrity.
The 2025 Ponemon survey backs this up, showing that high performers in identity and access management (IAM) are less likely to experience identity-related incidents than those with low IAM maturity.
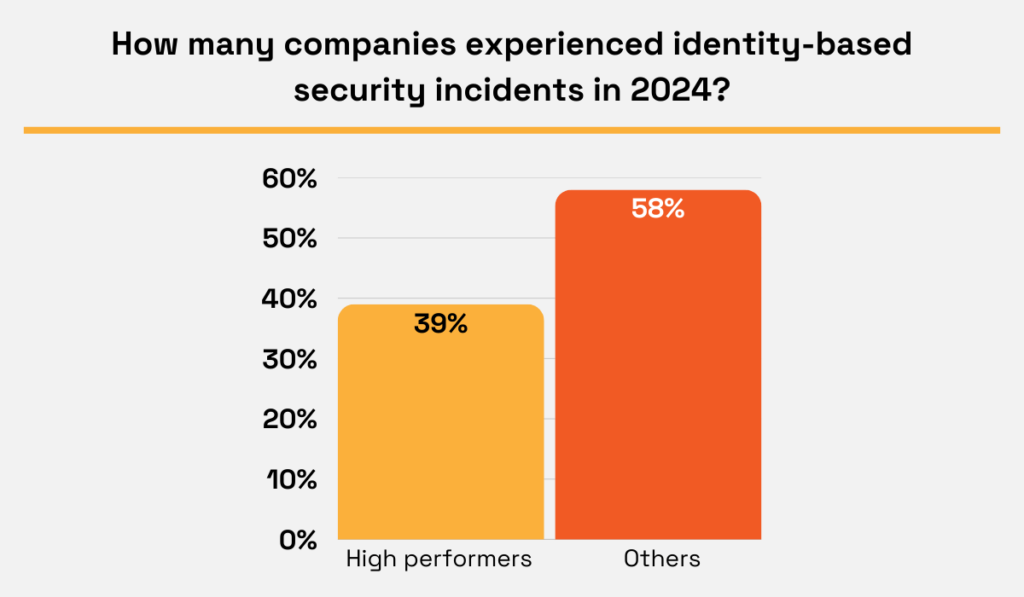
Illustration: Veridion / Data: Ponemon
And this is no small thing.
The same survey found that identity-based security incidents can have serious consequences, including loss of workforce productivity, reputational damage, reduced sales, and many more.
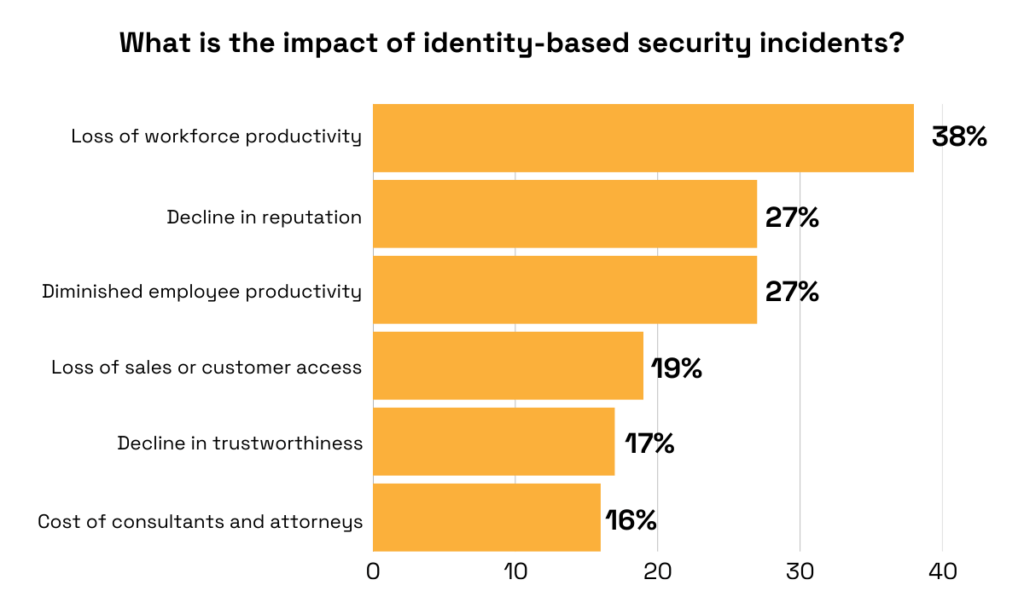
Illustration: Veridion / Data: Ponemon
In other words, access control isn’t just about meeting regulatory requirements, but also plays a major role in maintaining operational stability.
So, if you haven’t already, develop a clear access control policy that outlines who can access specific data, under what circumstances, and what actions they are permitted to take.
A major part of this task is deciding which access control model to implement.
Here are several common options to consider:
| Discretionary Access Control (DAC) | The owner of a resource decides who can access it and what permissions they have. Often used in environments where data owners need to retain control and customize permissions based on specific needs or relationships |
| Mandatory Access Control (MAC) | Access rights are governed by a central authority based on predefined policies rather than user discretion. Commonly used in highly secure environments |
| Role-Based Access Control (RBAC) | Assigns access rights based on defined roles within an organization. Efficient for organizations with clearly defined job functions and hierarchies |
| Rule-Based Access Control (RuBAC) | Uses a set of administrator-defined rules to determine access permissions. It allows for precise control and is suitable for organizations where conditions are clearly defined and consistently applied |
| Identity-Based Access Control (IBAC) | Grants access based strictly on an individual’s identity. Often used in scenarios where user-specific authentication is critical, such as systems managed by a dedicated group of personnel |
| Risk-Adaptive Access Control (RAdAC) | Access permissions are adjusted dynamically based on the current risk environment, emerging threats, or operational priorities. Implementing it requires advanced analytics and continuous monitoring to accurately assess risk |
While many other models exist, Role-Based Access Control is still one of the most widely adopted approaches.
For example, you can see it implemented in the Access Control Policy of the London School of Economics and Political Science.
The policy is straightforward, with many stakeholders assigned similar access levels.
However, certain accounts are designated as privileged, such as local administrators and domain administrators.

Source: London School of Economics and Political Science
Besides access roles, their policy also outlines related controls, including how privilege rights are allocated, how passwords are managed, and how penetration testing is conducted.
This helps them identify potential weaknesses and maintain the effectiveness of the document.
Be sure to include these in your own access control policy, as they add an extra layer of accountability and oversight.
In other words, this document cannot simply sit unchecked once it has been created.
It should be reviewed and updated regularly to ensure it stays relevant, effective, and aligned with evolving risks.
All other data ownership efforts fail if your teams aren’t properly educated on ownership responsibilities, quality standards, access policies, and more.
When employees aren’t clear on what needs to be done, how to do it, or why it matters, they’re far more likely to disregard the policies and controls you worked so hard to establish.
This, in turn, undermines your entire data governance strategy.
Perhaps that’s why, according to the 2025 Secoda survey, the top governance challenge for most organizations is increasing data literacy and accountability across teams.
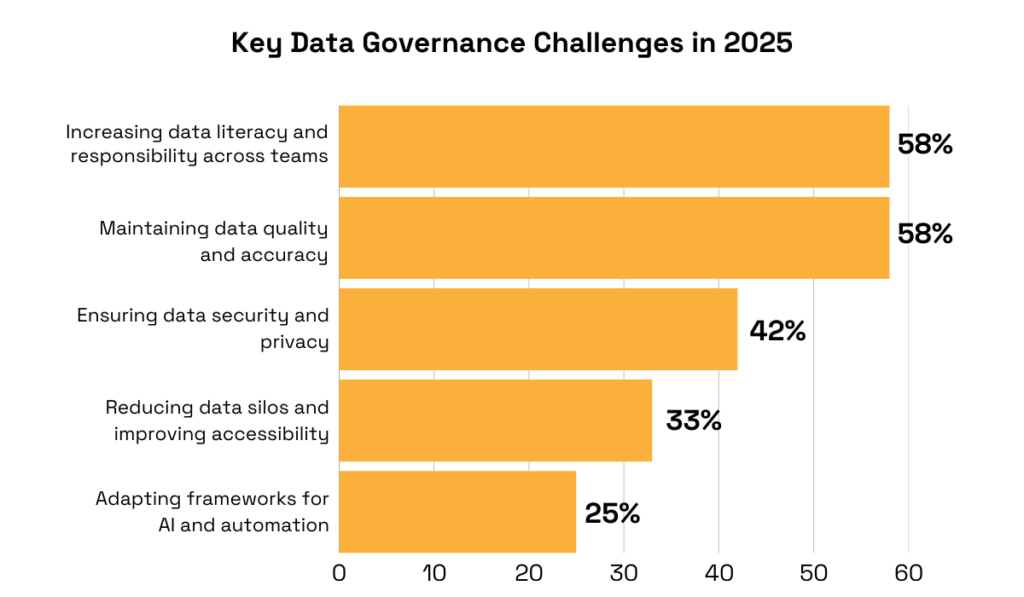
Illustration: Veridion / Data: Secoda
They understand they need to ensure that all stakeholders, not just technical teams, understand governance practices so that they can uphold them effectively.
The only way to achieve this is through regular, structured training.
This training can take many forms, including interactive workshops, e-learning modules, and more.
Research from KPMG shows that employees prefer a variety of training formats, so you’ll likely find that a blended approach works best.
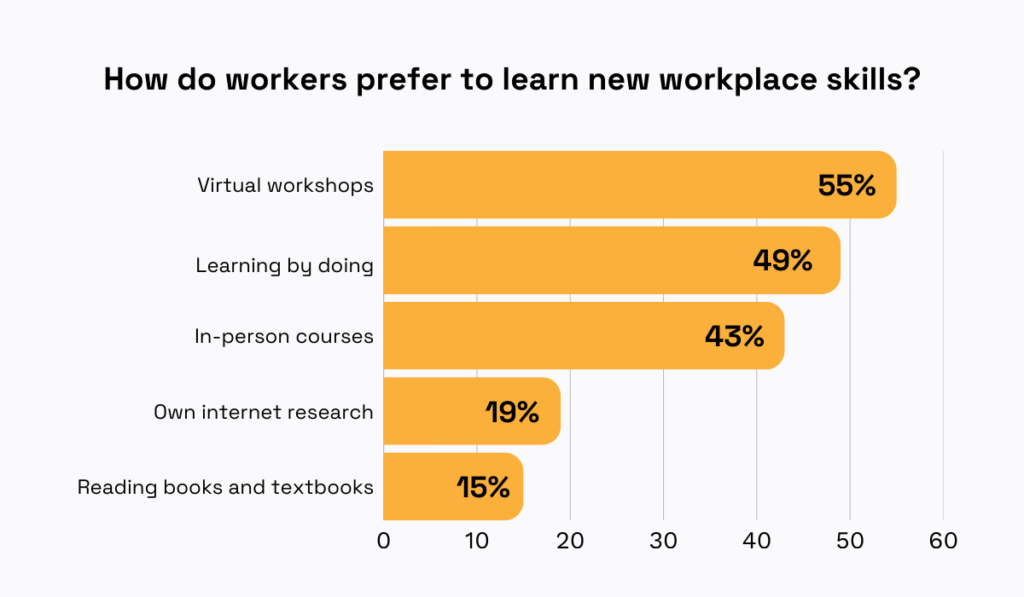
Illustration: Veridion / Data: KPMG
Regardless of the format, however, it’s absolutely vital to always emphasize the why.
That’s because data ownership issues rarely stem from a lack of technical knowledge.
More often, they arise from resistance to change driven by an unclear understanding of the purpose behind these new initiatives.
Dana Daher, Executive Practice Leader at HFS Research, a global research and advisory firm working with Fortune 500 companies, explains that this is a common issue across all business processes:

Illustration: Veridion / Quote: TechTarget
Therefore, always try to weave in the data ownership benefits during training.
Employees are far more likely to follow your policies when they understand how those policies protect the quality of their decisions, reduce risk, ensure compliance, and even improve profitability.
You’ve likely noticed that many of these data ownership best practices focus on rules.
You need to define and document who owns what, how data quality will be maintained, who has access to which data, and then ensure that teams are properly educated on these rules.
Yes, it can feel like a lot of upfront work, but it makes such a difference.
When there’s no guesswork, no time wasted searching for information, and no confusion or friction, meeting data ownership expectations becomes much easier for everyone involved.
So, take the time to develop these standards, document them in a way that’s accessible to all, and train your employees on how to use them effectively.
You’ll likely see significant improvements in no time.