
Blog
5 Data Enrichment Mistakes to Avoid Making
By: Stefan Gergely -
21 April 2026


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

Key Takeaways:
What if your data enrichment efforts were actually making your problems worse?
For example, if done improperly, enrichment could lead to targeting customers, suppliers, or partners based on inaccurate or outdated information.
While it can unlock huge value, enrichment only works when your base data is clean, and workflows are properly set up.
To get off to a running start, avoid these five mistakes organizations often make when beginning to enrich their data.
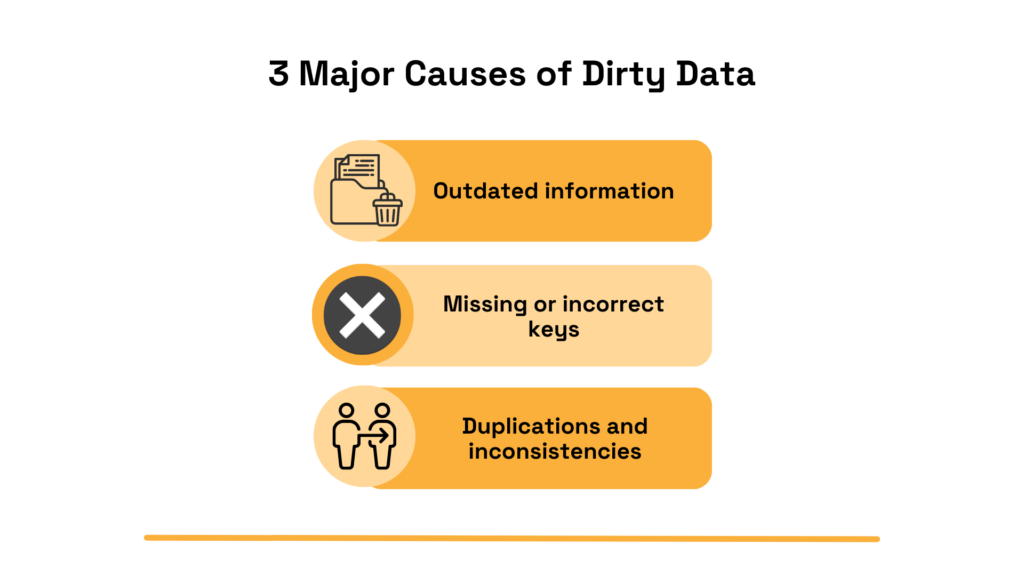
The first mistake is attempting to enrich incomplete, outdated, or duplicate records.
This often happens because organizations equate data enrichment with data cleaning.
However, the two serve different purposes.
Unlike data cleaning, enrichment doesn’t fix flawed data, but rather builds on top of it.
In many cases, this actually pushes errors deeper into the system and allows them to affect decision-making.
Nandini Bhamre, System Analyst at SPAR Solutions, a global consulting firm, agrees that enhancing inaccurate data tends to only amplify existing errors.

Illustration: Veridion / Quote: Nandini Bhamre on LinkedIn
The 2004 Bush campaign illustrates the stakes.
As Sasha Issenberg describes in his book, The Victory Lab: The Secret Science of Winning Campaigns, the campaign used voter data to deliver precisely targeted messages.
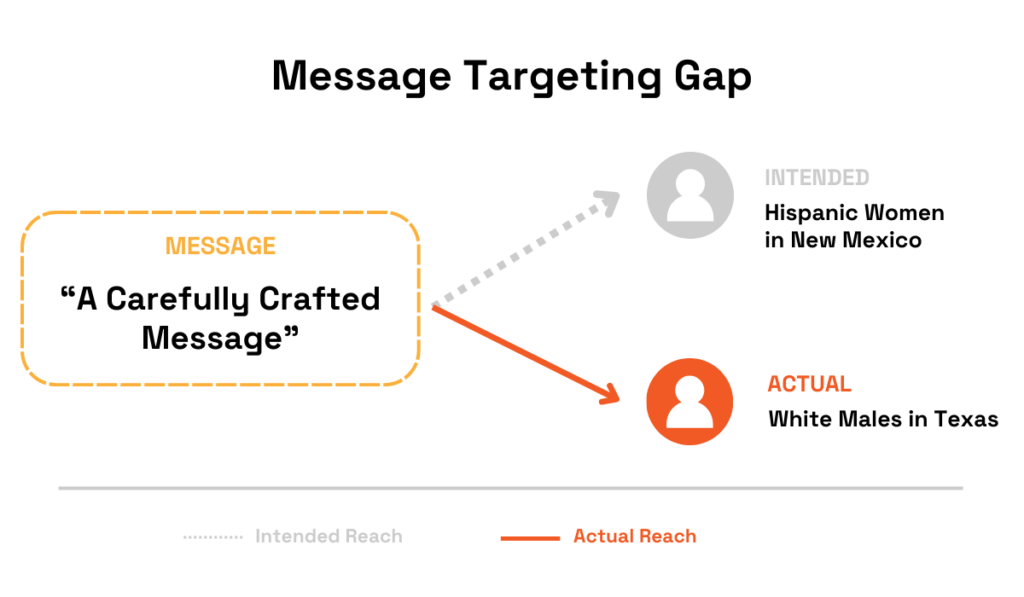
Hispanic women in New Mexico received education-focused outreach, while swing voters were reminded of September 11.

Source: Pacific Standard
While this approach can be highly effective, it relies entirely on accurate base data. In this case, that includes attributes such as race, gender, and location.
If that initial data is incorrect, enriching it with assumptions about desired messaging doesn’t fix the problem, but actually amplifies it.
For example, messages intended for “Hispanic women in New Mexico” could instead reach white male voters in Texas, potentially producing the opposite of the intended effect.
Source: Veridion
So, when inaccurate data is enriched, errors tend to propagate throughout the system.
That’s why teams need to ensure their data is clean before attempting to enrich it.
A good place to start is to watch out for the three common issues we already mentioned:
All of these issues can lead to costly business mistakes, especially once the data is enriched.
For example, duplicate records can cause systems to treat a single entity as multiple separate ones. This can result in expensive errors, such as duplicate payments to the same supplier.
Source: Veridion
Teams can mitigate these risks by performing validation checks.
Rudderstack, a customer data platform, lists several:
Null values and data type checks, for instance, focus on identifying missing or incorrect keys. Uniqueness and consistency checks, on the other hand, help teams identify potential duplicates and inconsistencies.
However, these traditional validation checks won’t fix outdated data.
You could approximate its freshness by looking at its last modified date, but that leaves a lot of room for error.
For instance, a record updated just a few days ago may already be outdated if the entity experienced significant changes since then.
The best solution is, then, to cross-reference your data with that of a third-party source.
This brings us to the next mistake to avoid.
Relying on a single data provider might reduce complexity, but could also introduce additional data issues.
The problem is that providers also have limited datasets themselves.
So, depending solely on one can easily lead to blind spots, bias, and coverage gaps.
For example, some providers primarily offer GTM-related data, such as extensive contact and intent information.
Others are more focused on providing data for MDM and operational decisions, like detailed product and service details on prospective suppliers.
Additionally, some providers cover global companies and contacts, while others focus exclusively on certain geographic regions, such as the EU.
One example of this can be seen below:

Source: HitHorizons
With that in mind, relying on just one of these APIs would leave significant gaps.
These limitations become especially prominent when companies try to apply one dataset to multiple use cases.
For example, using an MDM-focused dataset for GTM purposes won’t provide the right type of enrichment, and vice versa.
But limitations are clear even when companies are tackling just one use case.
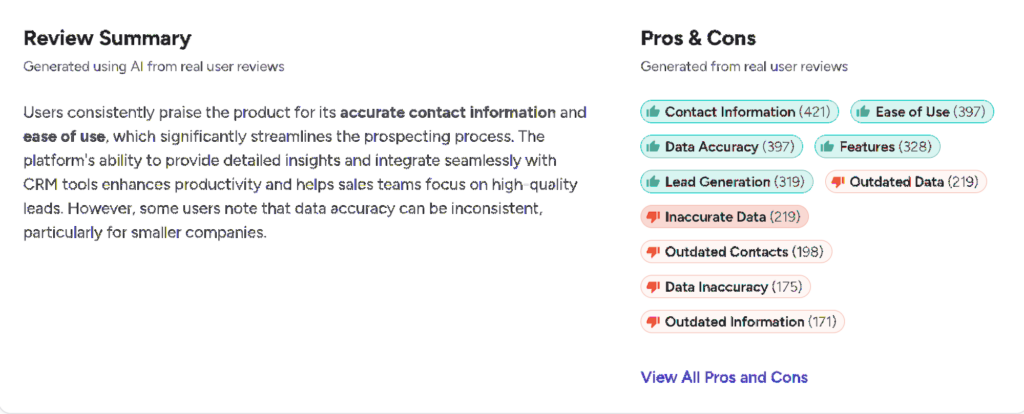
Take ZoomInfo Sales, for example.
Although the data enrichment tool receives overall very positive reviews, some users still report outdated and inaccurate data.
Source: G2
Every provider does well in some areas and less well in others.
To address this, organizations should combine multiple data sources and enrichment solutions.
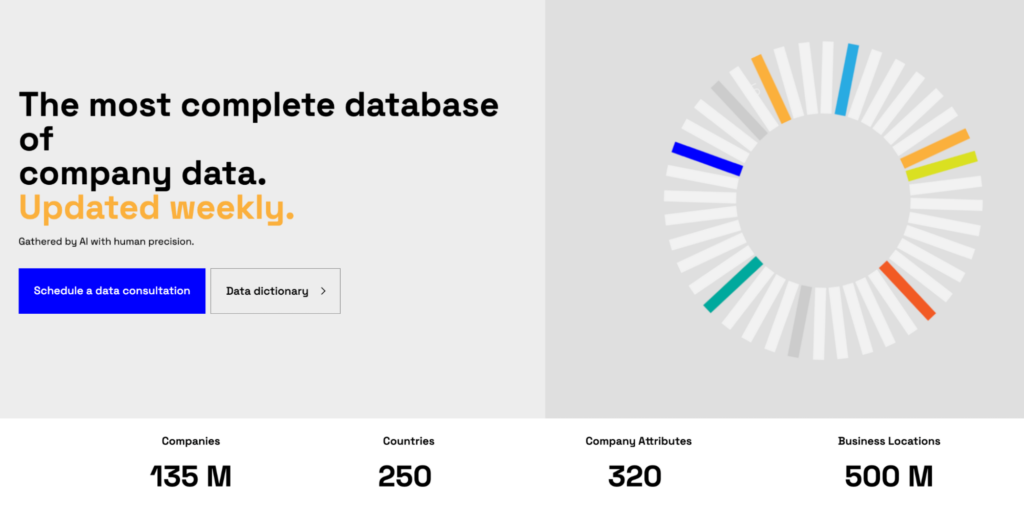
Enterprises could start with a solution that provides data usable across departments, like Veridion.
Our enrichment platform collects 320 data attributes on 135 million companies worldwide, with weekly updates that ensure freshness and completeness.
Source: Veridion
Its primary goal is to enable global company profile enrichment, entity matching, deduplication, and MDM.
While it’s primarily used by procurement and risk assessment teams, the extensive dataset provides a solid foundation for almost any department.
It includes everything from basic firmographics to product and service details, location intelligence, and ESG and sustainability metrics.

Source: Veridion
The data can also seamlessly integrate with other systems through a dedicated Match & Enrich API.

Source: Veridion
This allows organizations to combine multiple enrichment solutions.
One of the most popular strategies for this is the so-called waterfall approach, which splits sources into tiers.
The primary source, like Veridion, is used first to enrich the existing data.
If any gaps remain, the system can use secondary sources, then tertiary, and so on.
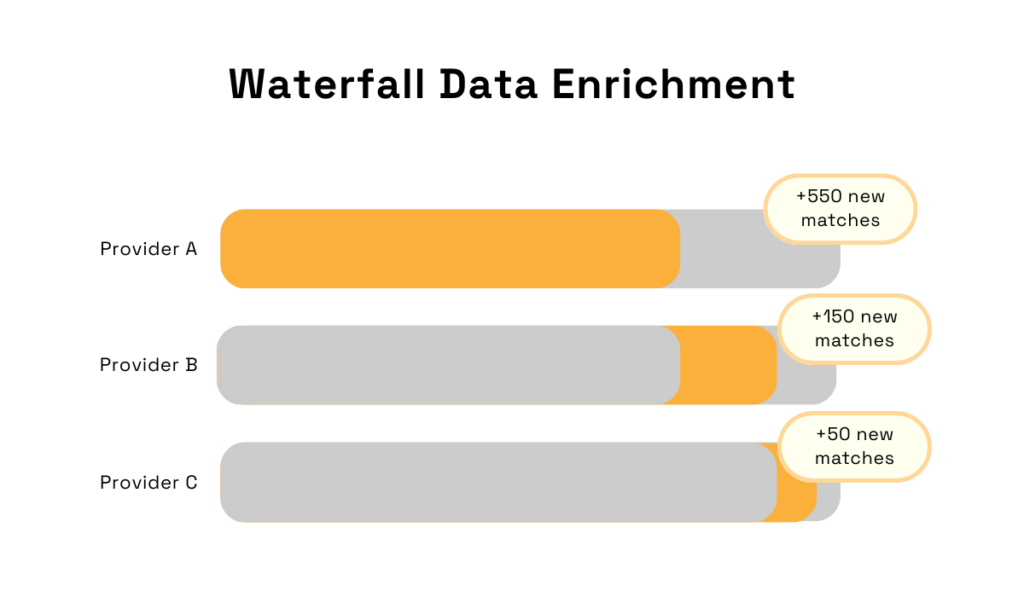
Source: Veridion
Of course, some gaps may still remain, but this strategy helps keep them to a minimum.
Another mistake is relying solely on automated processes with no humans in the loop.
Leaving no room for human review, governance, and exception handling invites errors and misclassifications.
As Stuart Winter-Tear, founder of the independent AI advisory practice Unhyped, notes, automation solutions that don’t allow for human intervention increase risk exposure.

Illustration: Veridion / Quote: Stuart Winter-Tear on LinkedIn
Jonathan Maurin, the CEO of the data enrichment tool Derrick, illustrates what this looks like in practice.
He references a use case where a sales ops manager set up automated enrichment.
Everything looked great on the surface, with the API enriching 5K contacts in just two days.
However, the tool confused “John Smith at Google France” with “John Smith at Google Ireland,” ultimately assigning the wrong phone number to 300 prospects.
The result? The sales team ended up spending two weeks calling Ireland before they noticed the error.

Source: Derrick
Of course, fully manual data enrichment isn’t viable either.
It requires more time and resources than most teams can afford, plus it may introduce even more errors than an automated system.
Additionally, not using readily-available automated solutions just wouldn’t make sense, especially when competitors are likely using them to move faster.
So, how can organizations solve this issue?
Maurin proposes adopting a hybrid 80/20 approach.
In this model, teams would delegate 80% of the work to the automated solution, but stay accountable for the remaining 20%.
Here is an example of what such a workflow could look like:
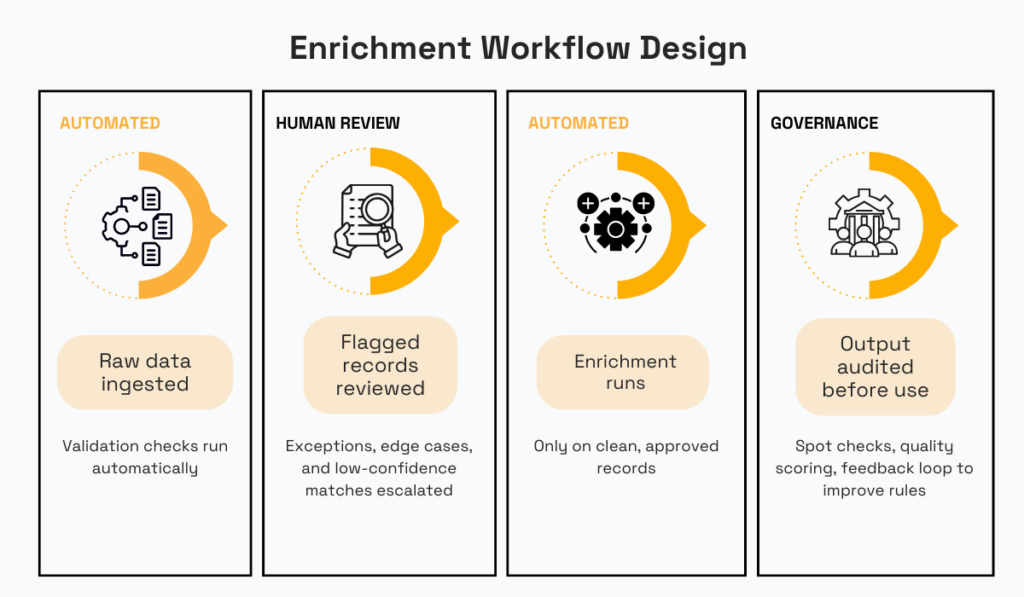
Source: Veridion
This model lets you leverage automation for easy wins, with humans handling more uncertain cases.
Teams can operationalize this by using confidence scores and defining clear rules for when human review is required.
If a confidence score is below a specified threshold, the solution should automatically flag it for review.
Veridion, for example, assigns confidence scores to each attribute based on two factors: completeness and relevance.

Source: Veridion
If a data point receives a low score, human experts should review and validate it.
Additionally, if you’re using the waterfall approach mentioned earlier, a low score can signal when it’s time to use another solution to fill the gaps.
Another common mistake is failing to validate enriched data.
This includes checking it for accuracy, relevance, and consistency before using it operationally.
For instance, before selecting a vendor, teams should ensure that the data they got on them is truly correct.
To see why this matters, consider an example from William Flaiz, founder of the data cleaning company CleanSmartLabs.
He shares that, after his team automatically enriched 50K contacts, about 15K came back worse than before.

Source: William Flaiz on Medium
Flaiz explains that the core issue was failing to set up any validation rules or fallback logic. Because of this, he claims, “every third-party value” was treated as an upgrade.
What this meant in practice was that existing data was indiscriminately rewritten without ensuring that new data was indeed more reliable.
In fact, for the aforementioned 15K contacts, that was clearly not the case.

Illustration: Veridion / Quote: William Flaiz on Medium
Flaiz’s team ended up essentially losing reliable contact information for prospects and had to spend significant time cleaning up their lists.
Depending on the use case, the effect could be even more detrimental.
Companies might get locked into a vendor that doesn’t meet their ESG criteria, or mislead investors with wrong performance metrics.
These risks can be mitigated by building validation steps into the workflow.
Here are three to consider:
We already discussed confidence scoring.
Cross-referencing can also be done through a waterfall approach, in which case you’re comparing data from multiple providers.
Additionally, data from providers can also be cross-referenced with official sources, such as state company registries.
Sampling, on the other hand, involves manually checking sample records to determine accuracy.
Samples can be picked at random or using custom rules.
In either case, if they show a high error rate, the rest of the data might not be reliable either.
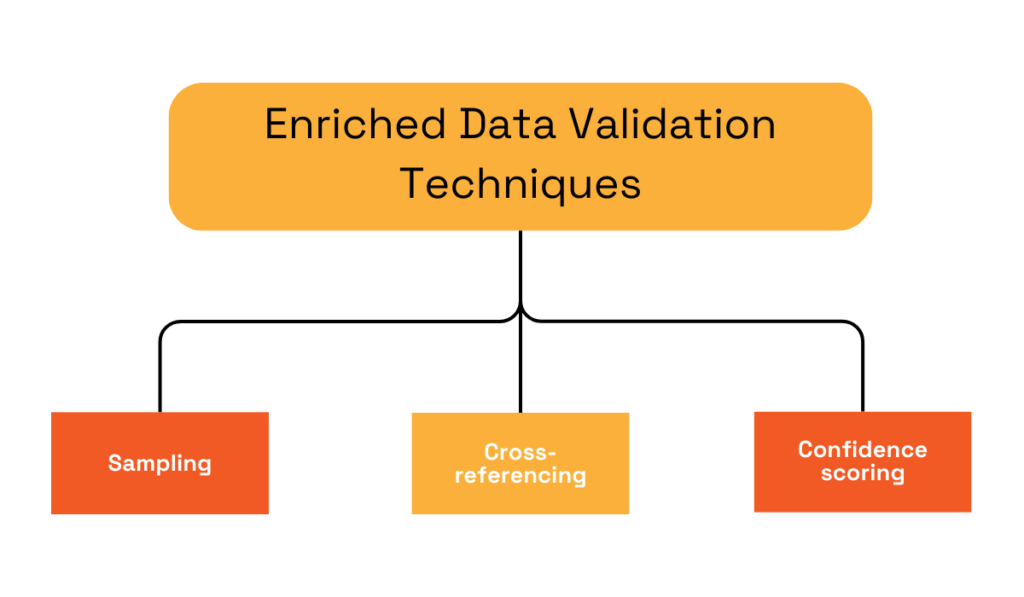
Source: Veridion
Also, before even choosing an enrichment vendor, inquire about their accuracy levels and whether they provide confidence scores.
How accurate is their data, and how do they calculate the scores?
It’s important to understand this upfront.
You could also inquire about their sources to get a better sense of the reliability of the original data.
Finally, failing to refresh decayed data can also undermine enrichment.
According to Data8, a data quality management company, average data decays at a rate of 30% per year.
In more practical terms, that would mean every 3 in 10 business data records go stale every year.

Illustration: Veridion / Data: Data8
Business data becomes stale quickly because of the fast pace of change within organizations.
Even smaller changes can lead to freshness issues. For example:
Companies may also change ownership and leadership, which could lead to losing key contact details altogether.
For example, McKinsey predicts that, by 2035, approximately 6 million businesses across the US will be on the market as their owners retire. This equates to about 665,000 exits per year.

Illustration: Veridion / Data: McKinsey
Changes like these may or may not be reflected in your records.
If they aren’t, you could face lost revenue, compliance violations, and operational setbacks.
For example, outdated contact lists may violate privacy rules. Outdated ESG and sustainability metrics can also impact compliance, as well as risk management.
On top of that, decayed data completely undermines the whole purpose of enrichment.
If existing data is stale, you might be enriching the wrong entities, creating a false sense of confidence, and losing money in the process.
Establishing regular refresh cadences can help.
According to Altss, a fundraising intelligence platform, this involves determining how often you’ll re-validate and update existing data records and fields to reflect new information.

Source: Altss
Different data types might require different cadences.
Some types change faster than others, so they might need to be reviewed and updated more frequently.
Here are a few examples of data types that tend to stay the same or change at a slower pace:
Other data, like employee count, might change more frequently.
So, it’s best to segment the types by volatility.
Some sources, like Octave, a GTM AI company, also recommend implementing more frequent cadences for the highest-value entities.

Source: Octave
Octave also recommends setting up automated, trigger-based refreshes.
Another thing to consider is segmenting your database by industry or company type.
Some entities in your database, such as tech startups, may undergo more rapid changes than others and thus require more regular checks.
The good news is that all of these data enrichment mistakes can be avoided with proper preparation.
Cleaning your data upfront, embedding validation steps in your workflows, and maintaining regular refresh cycles will maximize the impact of enrichment.
The sooner you take these steps, the sooner you can start leveraging your data in truly needle-moving ways.