
Blog
What is Data Ownership: Its Importance & Challenges
By: Stefan Gergely -
14 April 2026


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

Key Takeaways:
Behind almost every data protection penalty sits the same root cause: nobody owns the data.
When accountability over datasets is unclear, compliance gaps widen, quality erodes, and governance programs collapse.
This article breaks down what data ownership means, why it matters, and the three biggest challenges organizations face in implementing it.
Data ownership is the formal assignment of responsibility over a specific dataset to an individual or team within an organization.
It answers a deceptively simple question: who is accountable for this data?
That accountability spans several dimensions, each of which is critical to maintaining trust in the data your organization depends on.
Access control determines who can view or retrieve the data. Not every employee needs access to every dataset, and unchecked access is one of the fastest paths to a compliance breach.
Modification rights define who can update, transform, or delete records.
Without these guardrails, a single unauthorized edit to a supplier database or a customer list can cascade into flawed analytics, mispriced contracts, or broken workflows.
Security obligations ensure the data is protected against unauthorized access, breaches, and loss. This includes encryption, backup protocols, and audit trails that document every change.
Compliance responsibility ties the data to the regulatory frameworks it must satisfy, from GDPR and CCPA to industry-specific mandates like HIPAA in healthcare or SOX in financial reporting.
In practice, these responsibilities are distributed across three distinct roles. Each is accountable for a specific slice of that ownership.
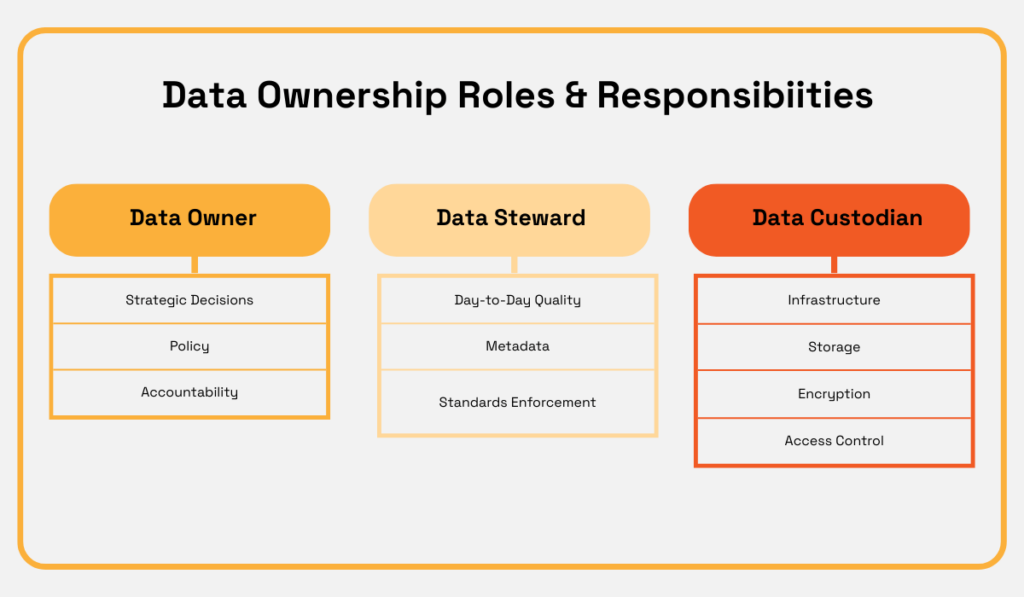
Source: Veridion
Data owners are senior business leaders. A VP of Sales might own the CRM data. A Chief Procurement Officer might own supplier records.
They set the policies, define access levels, and bear ultimate accountability for data quality within their domain.
Data stewards handle the day-to-day enforcement.
They maintain data quality standards, manage metadata, resolve inconsistencies, and serve as the bridge between business objectives and technical implementation.
Data custodians manage the technical infrastructure. Storage architecture, backups, encryption protocols, and access provisioning all fall under their scope, as defined by the owners’ policies.
When these roles are clearly assigned and well-coordinated, data moves through an organization with integrity.
When they break down, on the other hand, the consequences can be severe.
In February 2024, JPMorgan Chase, the largest bank in the United States, faced a roughly $350 million fine from federal regulators for providing incomplete trading and order data to surveillance platforms.
If you thought that this was a cyberattack, you’d be wrong.
It was a data quality failure, which meant gaps in trade reporting that had gone undetected across multiple internal systems.
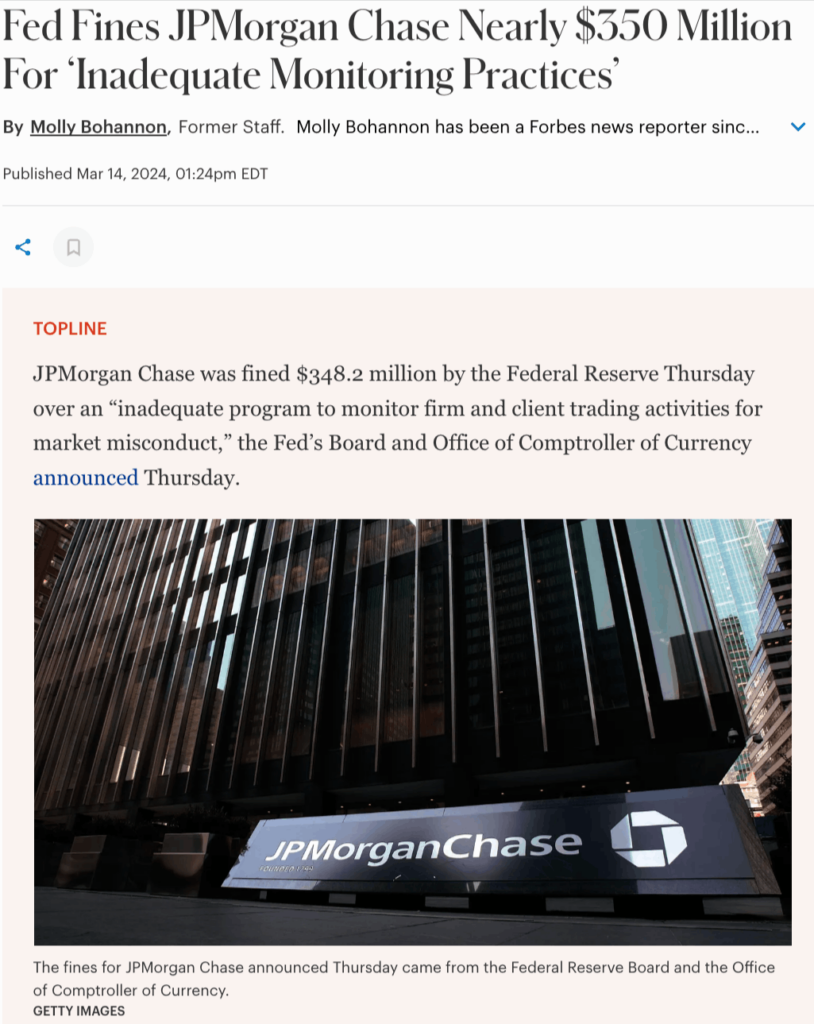
Source: Forbes
For a bank with JPMorgan’s resources, the fine was manageable.
But the reputational signal was clear.
Even the most sophisticated institutions fail when data ownership is fragmented across systems without proper validation at each handoff.
A clearer ownership structure, one that assigned accountability for validating trade data before it reached regulators, could have caught the gaps upstream.
But ownership on its own is not enough. It needs to sit within a broader governance framework to deliver real value.
Data governance defines the rules, while data ownership decides who enforces them.
Without clear ownership, governance policies become well-documented, widely circulated, but rarely followed.
When every dataset has a named owner, accountability stops being abstract.
Someone is responsible for ensuring the data is accurate, compliant, and accessible to the right people at the right time.
That clarity is rapidly becoming the top strategic priority for data leaders.
According to Atlan’s 2024 Data Culture Report, more than 65% of data leaders now rank data governance as their number one initiative, placing it well ahead of AI, data quality, and self-service analytics.
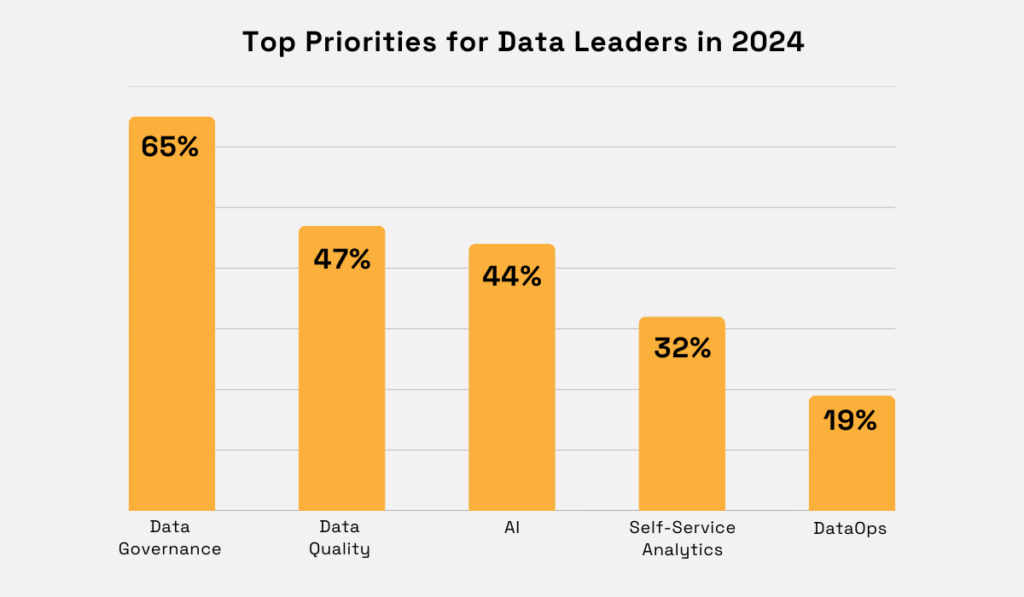
Illustration: Veridion / Data: Atlan
Simultaneously, 62% of organizations reported that data governance was the single greatest impediment to AI advancement, citing concerns around data lineage, quality, privacy, and security.
The connection is easy to make.
You cannot build reliable AI models, produce compliant reporting, or make confident strategic decisions on data that nobody owns.
And when ownership gaps meet regulatory scrutiny, the financial consequences are immediate.
For example, in 2024, Ireland’s Data Protection Commission fined LinkedIn €310 million for processing user data for behavioral analysis and targeted advertising without a valid legal basis.
The investigation revealed that LinkedIn failed to obtain proper consent, could not demonstrate legitimate interest, and did not adequately inform users about how their personal data was being processed.
DPC Deputy Commissioner Graham Doyle stated that processing personal data without an appropriate legal basis represents a serious violation of data subjects’ fundamental rights.

Illustration: Veridion / Quote: Irish Data Protection Commission
LinkedIn’s case is far from isolated.
In the same year, Dutch regulators fined Uber €290 million for transferring European drivers’ personal data to the United States without adequate safeguards.
Investigators found that Uber had stopped using Standard Contractual Clauses years earlier, leaving sensitive data exposed without legal protection.
And in December 2024, Meta received a €251 million penalty for a Facebook data breach.
They had exposed the personal information of 29 million users globally, including sensitive details like religious views and group memberships.
In every case, the enforcement actions pointed to the same structural failure: no clear ownership over how data was collected, processed, transferred, or protected.
The DLA Piper GDPR Fines and Data Breach Survey confirmed this pattern.
Aggregate fines in 2024 alone reached €1.2 billion, with enforcement expanding well beyond Big Tech into financial services, energy, and healthcare.
More importantly, regulators have begun specifically calling out failings in governance and oversight structures, and even exploring whether directors can be held personally liable for GDPR violations.
This clearly gives rise to a pattern that is hard to ignore.
Regulators are no longer just penalizing breaches. They are penalizing the absence of the governance structures that should have prevented them.
So what stops organizations from getting data ownership right?
Recognizing the importance of data ownership is the easy part.
Implementing it across a large enterprise, with legacy systems, distributed teams, and competing priorities, is where most programs stall.
Three challenges come up again and again.
Data ownership programs fail most often when they lack sustained backing from the C-suite.
Without executive sponsorship, governance becomes an IT initiative rather than a business imperative. And IT-driven governance rarely gets the cross-functional buy-in it needs.
AIM Consulting identifies this as one of the primary contributors to failure.
When IT drives data governance initiatives without strong business support, the program stalls at the department level.
The business has to own its data and drive its own transformation.
IT cannot be effective without the involvement of the people in charge of all affected aspects of the business.
This makes a compelling case that leadership across the board has to be involved.
Dr. Peter Aiken, President of DAMA International, estimates that fixing poor data governance consumes 20–40% of IT budgets.

Illustration: Veridion / Data: Dataversity
That is money diverted from innovation, product development, and growth, and spent instead on cleaning up preventable problems.
The downstream impact on transformation efforts is equally stark.
McKinsey & Company research consistently finds that the majority of large-scale digital transformation programs fail to meet their objectives.
This is mostly due to poor data quality and fragmented governance.
The programs start as technology projects, without business leaders taking ownership of the underlying data, and rarely deliver the outcomes they promised.
Yet many executives still view data ownership as a technical concern rather than a strategic one.
The most effective way to shift that perception is to frame ownership in terms the C-suite already prioritizes: revenue and risk.
Donna Burbank, Managing Director at Global Data Strategy, recommends reframing the language entirely.

Illustration: Veridion / Quote: TDWI on YouTube
Instead of talking about metadata management, talk about giving leaders a complete view of their customers. Instead of data lineage, talk about reducing the time to close a deal.
Also, you should start small. Focus on one or two data domains with visible business impact and scale from there.
Executive support always comes with a demonstration of value.
And once leadership sees measurable outcomes, the appetite for governance investment tends to grow quickly from there.
Even with executive backing secured, large organizations face a second challenge that is harder to resolve with persuasion alone.
Figuring out who owns data when it lives across a dozen different systems.
In large enterprises, data does not sit neatly in a single system.
A single supplier record might originate in an ERP, get enriched through a third-party data provider, flow into a procurement platform, and surface in a risk management dashboard.
At each handoff, the question of ownership gets murkier.
This fragmentation is indeed a concern.
According to MuleSoft’s Connectivity Benchmark Report, 90% of organizations struggle with isolated and disconnected data environments — a figure that has remained stubbornly consistent year after year.

Illustration: Veridion / Data: MuleSoft
When data flows through multiple systems with no clear accountability at each stage, problems compound quickly.
This leads to duplicate records and conflicting versions of the same dataset across departments.
Nobody knows which source is authoritative, and every team operates on a slightly different version of the truth.
One practical approach to untangling this complexity is the RACI matrix.
RACI is a responsibility assignment framework that defines four distinct roles for every data asset or process:
| Responsible | the person or team doing the hands-on work |
| Accountable | the individual with ultimate ownership and sign-off authority |
| Consulted | stakeholders who provide input before decisions are finalized |
| Informed | people who need to know about changes but are not directly involved in making them |
Here’s what the RACI table might look like in practice:
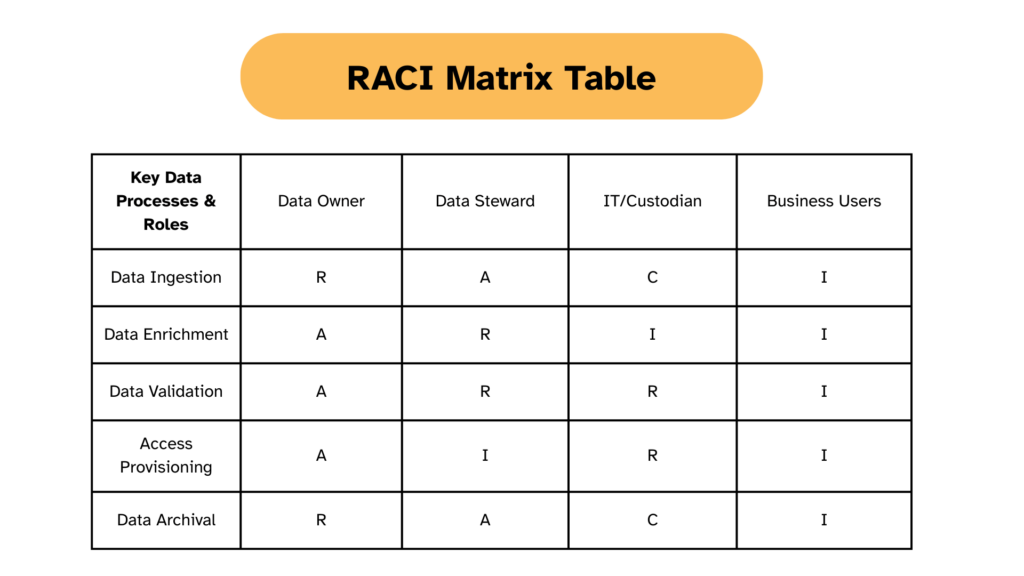
Illustration: Veridion
Applying a RACI matrix to each data domain forces organizations to confront ambiguity head-on.
For example, when a supplier record flows from your ERP into a procurement tool, the RACI matrix makes explicit who is accountable for validating the data at each stage.
The procurement team might be responsible for updating supplier classifications, while the data steward is accountable for ensuring those classifications meet governance standards.
Without this level of specificity, ownership disputes go on increasing. Departments point fingers. Data quality degrades because nobody considers it their problem.
When every dataset, field, and process has a named accountable party, handoff points become clearer, and data flows more predictably across systems.
But even the most well-defined accountability structures cannot compensate for data that is fundamentally unreliable.
Assigning ownership of data that is inaccurate, incomplete, or outdated is like putting a name on a broken asset.
The accountability is clear, but the underlying problem remains.
And these problems can wreak havoc.
For example, Gartner estimates that poor data quality costs organizations an average of $12.9 million per year.
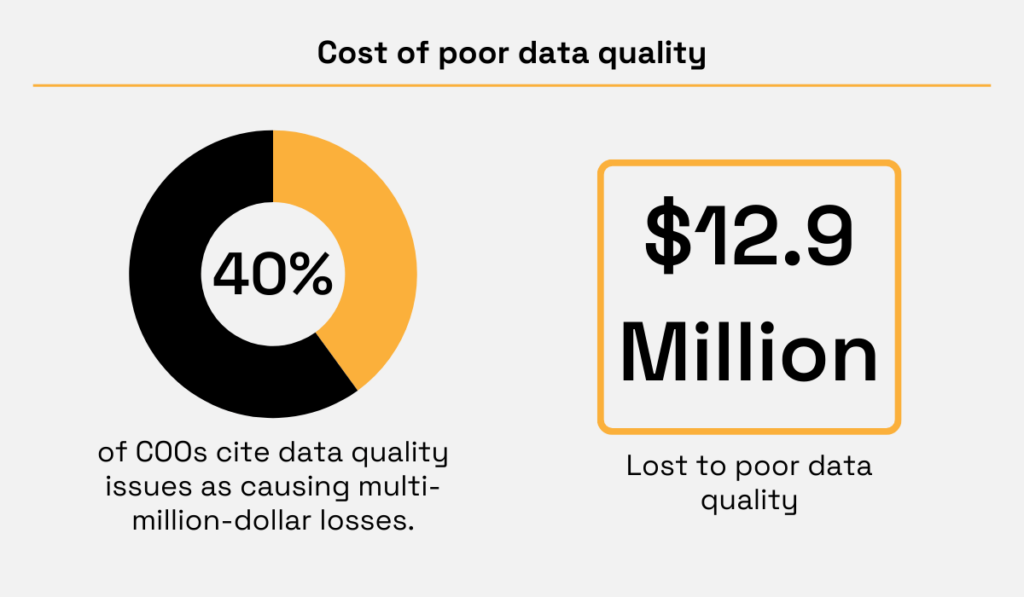
Illustration: Veridion / Data: Gartner and IBM
The challenge is that modern business data is inherently volatile.
Employees change roles. Companies rebrand, merge, or shut down. Product lines shift, and addresses become obsolete.
The rise of remote work, frequent job changes, and rapid corporate restructuring have all accelerated this trend.
When this data enters your systems from dozens of sources, across procurement platforms, CRM tools, financial databases, and vendor portals, staying on top of quality becomes nearly impossible through manual processes alone.
A 2024 study by HRS Research and Syniti found that fewer than 40% of Global 2000 companies even have the metrics or methodology in place to assess the business impact of poor data quality.

Source: Syniti
Most organizations do not know how much their bad data costs them.
The most effective response to this challenge, especially in B2B data, is automated data enrichment and validation.
Rather than relying on manual checks that cannot keep pace with the volume and velocity of incoming data, AI-powered enrichment platforms continuously normalize, verify, and deduplicate company records against authoritative external sources.
This is exactly where platforms like Veridion come into play.
Veridion’s Match & Enrich service cross-references your existing company records against a global database of over 120 million businesses, automatically validating and enriching fields like company name, address, industry classification, and operational status.
You can learn more about Veridion’s data enrichment service in the video below:
Source: Veridion on YouTube
There’s no need to assign a data steward.
You get continuous, automated quality control that keeps your datasets current and reliable, week over week.
This kind of automated validation strengthens data ownership instead of replacing it.
When data owners can trust that their datasets are accurate and up to date, they spend less time firefighting quality issues and more time driving strategic value from the data they are responsible for.
Data ownership is not a policy you publish and forget.
It is an ongoing commitment to clarity — clarity over who manages each dataset, who enforces quality standards, and who answers when something goes wrong.
The organizations that get this right build governance programs that function under pressure, survive regulatory scrutiny, and produce data their teams trust enough to act on.
Start by naming your owners. Map your accountabilities. Automate your quality controls.
The data will not govern itself.
And the organizations that treat ownership as infrastructure will be the ones that build AI systems worth trusting and governance programs worth keeping.