
Blog
Do We Trust Our Data?
By: Alin -
10 February 2021


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

Everyone knows what you mean when you ask them, “do you trust the data you use?” And everyone WILL answer you. Perhaps not articulately, but they will have an opinion. “It’s decent”, or “it’s crap”, they will say, and so on.
But don’t ask anyone to define what trust is. Sure, the brave ones (like this author) will try to recite the ingredients that make up data quality as though it’s some sort of immutable law. People will try to tell you the core “pillars” or the desirable attributes of high-quality data, of course.
But no matter what formula you choose, no matter the words we use to share our wisdom, I would challenge all of us to make the following bet: that, if the data we use had all of the required attributes and ingredients, we would put absolute trust in that data.
I suspect many of us would take that bet, whether we could articulate what that trust is or not. After all, if the ingredients in the recipe are of the highest quality, shouldn’t the end (business) outcome be assured?
This brings us to the actual problem, which I’ll frame as a question to you: has our confidence in driving out our goals and objectives in business – whether financial, operational, technical or otherwise – actually improved in the face of the massive investment we’ve made in data?
Before we answer that, let’s do a reality check as we near year-end 2021.
Over the last, say, 5 years, most large organizations have invested mightily in their data and everything to do with data. In no particular order, a typical checklist might look as follows:
And yet…
Do we trust our data? Have we made the progress we should have towards making confident decisions considering the massive investments that we’ve made?
In my quest to answer this rather important question, I came across this insightful snapshot from the team at Snaplogic. (Take a moment to download their terrific survey on data trust here.)
They surveyed 500 IT Decision Makers (ITDMs) at medium and large enterprises across the US and UK in 2020 – certainly a solid representation – on the various data and analytics challenges facing their organizations, along with the related and concerning levels of data distrust.
Although I wrote earlier that a precise definition of trust is a tough undertaking, many of us could agree that there are some essential ways of determining whether trust in the data is warranted or not.
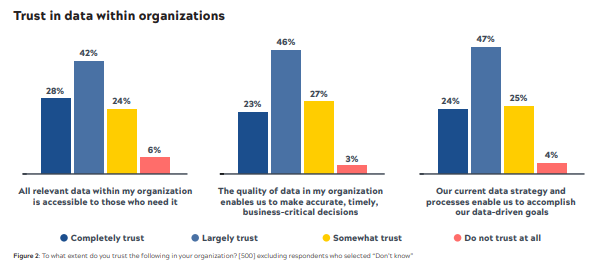
Which is exactly the approach Snaplogic implemented by putting these questions forward to their audience: can I find the data when I need it? Does the quality of the data let me make good and timely decisions? And, does our data strategy and processes demonstrate a positive link to our goal achievement?
Depending on your disposition (glass half-full? half-empty?), you might read the results below as either (a) about 75% of us don’t completely trust our data or (b) about 30% of us are a LONG way from trusting our data.
I’d argue both views suggest there’s a problem!
Naturally, we want to know what the root causes are. And this is where it gets interesting because the answers aren’t that complicated or surprising!
In fact, the majority of decision-makers had similar views on what the most significant root causes are, based on the following situations occurring in their organization at least “sometimes”:
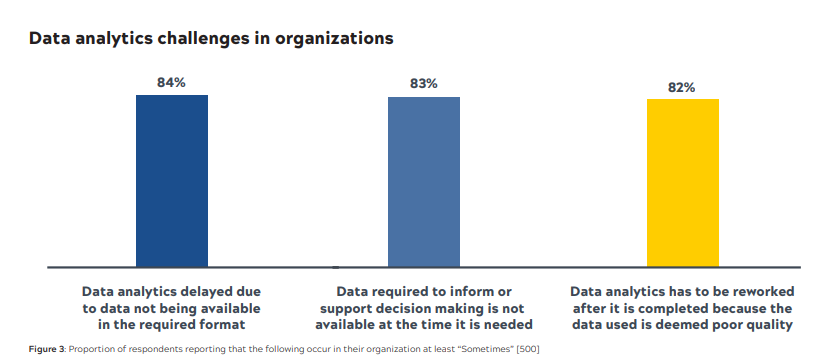
The most shocking aspect of these answers is that NONE of these issues have gone away in the past 20 years. That’s despite 20 years of investment in infrastructure, tools, and people.
Obviously, we don’t know the details behind each of the respondent’s answers. But, with 500 respondents, we can be reasonably sure that these companies are like most that we work at, or sell solutions to.
And, by “like”, I mean that they’ve invested in modern infrastructure, modern tools and they’ve staffed up even a small data & analytics team to deliver on the promise of extracting value from their first-party – and maybe even third-party – data.
So, isn’t it surprising that the challenges driving the distrust in data are SO tactical?? Can these issues be addressed?
Of course they can….and we’d be remiss in not mentioning that Soleadify can help.
I wrote earlier about the traditional way of measuring trust in data – by defining data quality according to its attributes.
The use of the 4Vs – volume, variety, velocity and veracity – is one of the most popular frameworks to define data quality with some people adding a 5th “v” to include value.
I’m sure there are other ways, other methods and certainly, other attributes and related metrics to measure quality.
But, definition or frameworks like these don’t directly capture or measure the impact that data has on driving business outcomes, whatever the intended use case is trying to achieve.
To start us down the path of a Data Trust definition, let’s first ask ourselves the question: what do we expect of our data?
We all have various business goals and know the KPIs associated with them; of course, this applies to how we manage risk, improve operational efficiency or the interactions with our clients.
Rather than creating a completely separate approach to defining the value (based on trust) that we derive from data, let’s consider evaluating our data through the lens of our existing goals and KPIs. We can do this by asking ourselves questions such as:
This exercise will help us define the expectations we have, not from the data itself, but from its impact in our company.
I’d argue that’s a far more important goal, in most cases.
For those that rely on external data, that are perhaps excited about the possibilities that new sources of alternative data can add much needed insights to your existing data ecosytem, we’d love to talk.
Let us share with you a case for the quality attributes of our data, talk about the impact of our data acquisition methodologies and sources, And even show you how our data can enrich your existing data assets.
But if I had to pick one aspect of our data that can address your current concerns around data trust or mistrust, it would be this: our data drives results.
Wouldn’t the combination of the right qualities or attributes AND the knowledge that the data actually performs be ideal?
If you agree, I’d be shocked that better results (that come from better decisions) wasn’t the best way to address a lack of trust in data.
What do you think? We’d love to hear from you! Find out more about our story here or connect with us on LinkedIn here.