
Blog
How to Manage Business Data More Effectively
By: Stefan Gergely -
31 March 2026


We love our data, and now that you're here, you're one step closer to loving it too.
A wide sample of data, so you can explore what is possible with our data
Choose ->
built with procurement in mind. Focused on manufacturers, products and more
Choose ->
built with insurance in mind. Focused on classifications, business activity tags and more
Choose ->
built with sustainability in mind. Focused on sustainability commitments, and environmental and social governance insights.
Choose ->
built with strategic insights in mind. Focused on market trends, competitor analysis, and industry-specific data
Choose ->

Keep up to date with our technology, what our clients are doing and get interesting monthly market insights.

How many strategic decisions in your organization are based on incomplete or inconsistent data? And how do you even know when it’s inconsistent?
In large enterprises, business data impacts everything: procurement, risk, compliance, finance, analytics systems, and more.
So when that data is fragmented or unreliable, one small decision can snowball into a disaster.
That’s exactly why we’ve compiled this guide.
Read on to learn five tips to manage business data more effectively, so you can improve visibility, reduce risk, and make decisions grounded in accurate, enterprise-wide intelligence.
A data strategy built on inconsistent names is like a map with shifting labels.
If your company records the same supplier under five different names across ERP, CRM, and risk platforms, you don’t have five suppliers, but just one, plus five versions of the truth.
Normalization is all about standardizing company names, legal entities, identifiers, and classification systems across every system that stores your business data.
When records are inconsistent, all departments suffer:
What should be a shared foundation thus becomes a source of friction.
The financial impact is not abstract, either.
Gartner estimates that poor data quality costs organizations an average of $12.9 million per year. Much of this shocking number is closely tied to inconsistent or fragmented master data.

Illustration: Veridion / Data: Gartner
In B2B environments, even small variations, like “ABC Holdings Ltd.” versus “ABC Ltd.”, can distort spend analysis and obscure concentration risk.
Outdated records only compound the issue.
They can hide ownership changes or legal entity restructures, and these materially affect compliance and third-party risk assessments.
Standardized identifiers are thus essential.
Global enterprises rely on tax IDs, DUNS numbers, LEI codes, and industry classifications such as NAICS and NACE to distinguish entities accurately.
Without these anchors, legal entities blur together across jurisdictions, making cross-border reporting completely unreliable.
In fact, inconsistent classification systems create issues that seep through to pretty much all areas you can imagine.
Take ESG reporting or sector-specific regulatory disclosures.
ESG metrics become, of course, unreliable, and regulatory reports risk omitting entities that fall under specific disclosure requirements.
To address these challenges, begin with a single source of truth for legal entity data.
Define mandatory fields:
Then, enforce validation rules at the point of entry.
Next, implement common normalization techniques used in B2B datasets, like deduplication algorithms, fuzzy matching to identify naming variations, and automated validation against authoritative registries.
Harmonize classification taxonomies by mapping internal categories to recognized standards such as NAICS or NACE.
That way, you make sure ERP, CRM, and risk platforms interpret supplier data consistently.
Finally, establish synchronization protocols across systems.
When a record is updated in one environment, changes should cascade automatically to others through APIs or master data management workflows.
The visual below sums up the entire process:
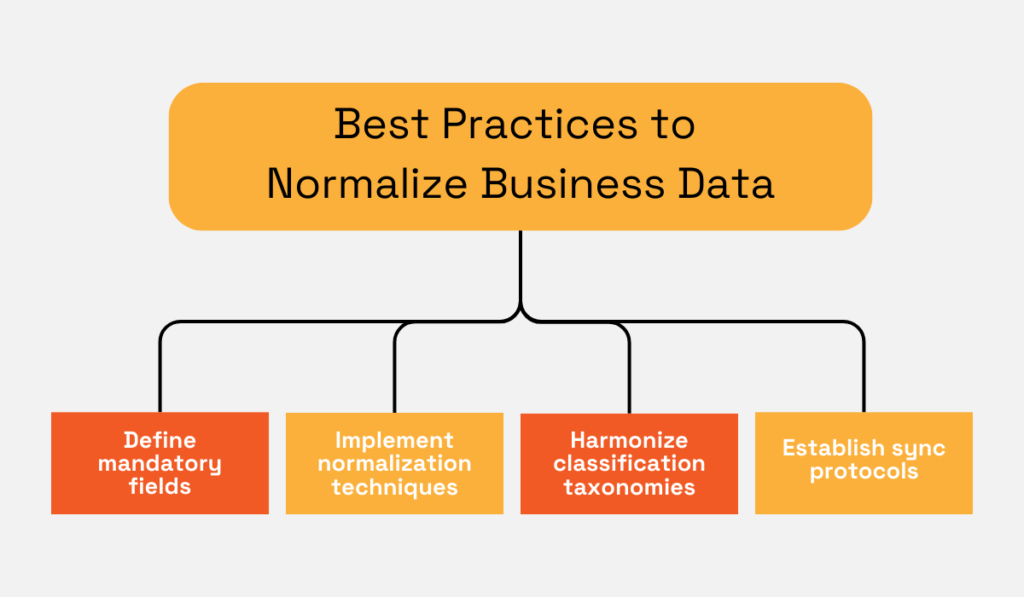
Source: Veridion
And here’s a direction to keep in mind.
When normalization is systematic rather than reactive, business data becomes usable across procurement, risk, compliance, and analytics.
That’s what you need to build a stable foundation for enterprise-wide decision-making.
Building on our previous map comparison, running a global enterprise on fragmented data is like steering a ship with five different compasses.
When procurement, finance, risk, and analytics operate from disconnected systems, visibility fractures:
That’s why fragmentation slows reporting and increases operational and compliance risk.
The risks of a decentralized data architecture are tangible.
If, for example, a risk platform flags a supplier for sanctions exposure, but that information does not sync with procurement systems, transactions may continue unchecked.
On the other hand, if finance updates payment terms without alignment with supplier master data, spend analysis may misrepresent exposure.
Fragmentation creates blind spots, and blind spots create risk.
Centralization changes the equation.
By consolidating records into a unified data environment, you create a shared foundation for decision-making.
So your teams don’t have to work double hard to reconcile conflicting reports. They just rely on a single version of the truth that everyone trusts.
The goal is not to eliminate specialized tools, but to ensure that they communicate through a shared data backbone.
Here’s a quick look at centralized data architecture done right (as opposed to a decentralized one):
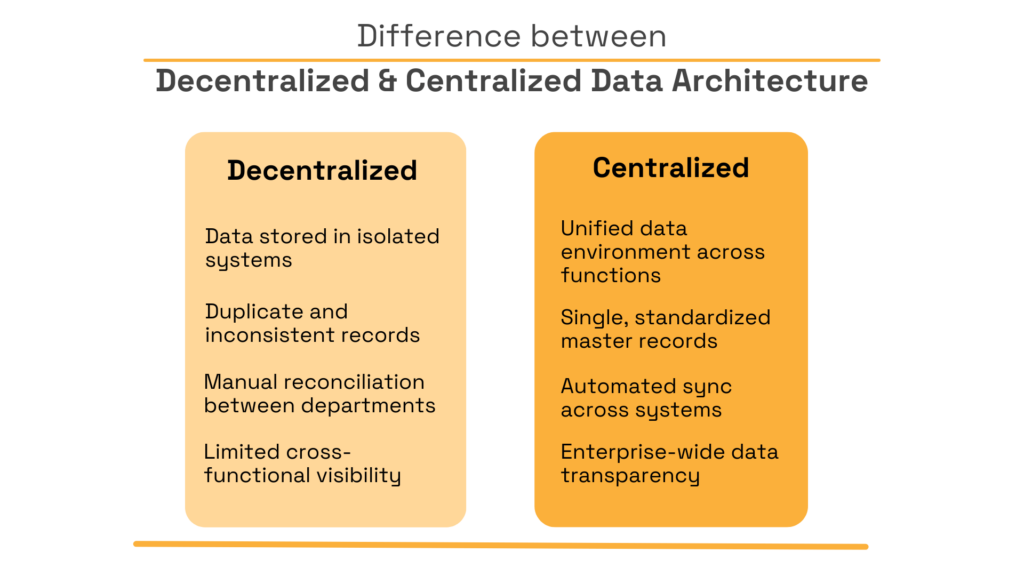
Source: Veridion
Centralized architecture can take several forms, but most enterprises begin with a master data management (MDM) layer that standardizes core entities across ERP, CRM, and procurement systems.
APIs then integrate third-party intelligence into this governed environment—this is the bit that makes sure external insights flow directly into the shared data backbone.
Cloud data lakes or warehouses aggregate structured and unstructured information on top of this foundation, enabling unified dashboards powered by a synchronized, enterprise-wide dataset.
Some of the world’s biggest companies have recently implemented this model to unlock huge performance gains.
Take Unilever, the third-largest consumer goods company. Over 400 brands sold to over 190 countries, with 175,000+ employees.
Over the past decade, the company consolidated roughly 250 separate ERP systems into just four standardized global SAP platforms as part of a large-scale digital transformation.
Simply put, they centralized financial and operational data into a unified digital core.
Unilever thus reduced its month-end financial close from three days to one. And they significantly improved real-time reporting accuracy.
Steve McCrystal, Unilever’s Chief Enterprise Technology Officer, explained how their unfathomable quantity of data requires a unified, centralized approach:
“Our enterprise data platform contains 8 petabytes of data, fuelled by 25,000 data pipelines collecting and processing new data each day… One of our primary challenges is to consistently keep everything running smoothly across various functions and markets.”
No matter your company size, disconnected systems increase operational overhead and compliance exposure. Centralization, conversely, improves accessibility and strengthens oversight.
Ultimately, you get a coherent, enterprise-wide view of business data.
Even the most advanced data infrastructure will deteriorate without clear ownership and accountability.
Effective business data management begins with governance.
That’s a defined structure that clarifies:
According to HICX’s 2023 research, in 83% of organizations, ownership of supplier data is split across multiple functions.
This explains why accountability often blurs in practice.

Illustration: Veridion / Data: HICX
Without governance, though, normalization efforts unravel, centralized systems drift, and silos quietly re-emerge.
Common data governance frameworks include DAMA-DMBOK or COBIT. Here’s a quick comparison between the two:

Source: Veridion
Both frameworks emphasize accountability, stewardship, and policy enforcement.
At the enterprise level, governance typically involves three core roles:
| Data owners | are accountable for the strategic value and integrity of specific datasets |
| Data stewards | manage day-to-day quality, ensuring records are accurate, complete, and aligned with standards |
| Data custodians | oversee the technical storage, security, and movement of data across systems |
When these roles are undefined or overlapping, inconsistencies snowball fast.
For example, one team updates supplier data while another maintains outdated records—this immediately generates duplication and compliance gaps.
Effective governance defines naming standards, mandatory fields, validation rules, and clear escalation paths.
A clear example is ASN Bank in the Netherlands.
They built a centralized data governance model to strengthen regulatory compliance and eliminate duplicated data management across teams.
Before, their risk, reporting, and data warehouse functions often managed the same concepts in parallel, which created lots of inconsistencies and audit friction.
So they introduced:
This improved compliance significantly.
As Kasper Kisjes, their Enterprise Data Catalog Implementation Lead, noted, bridging data silos meant they were no longer “managing the same concepts three or four times.”
Organizations that formalize these types of structures improve data consistency, strengthen audit trails, and enhance reporting accuracy.
Business data is one of your organization’s most valuable assets… and one of its most exposed.
Effective data management doesn’t end with accuracy and accessibility. It absolutely must include safeguards against misuse, external breaches, and regulatory violations.
Without structured security controls, even well-governed data environments can become huge liabilities. A single incident can undermine years of operational progress and damage stakeholder trust.
That’s why there are regulatory frameworks such as GDPR in the European Union or CCPA in California in place.
Over time, they raised data protection from a technical concern to a board-level priority. Consent, data access, retention, and breach notification are not to be taken lightly.
What’s more, non-compliance can result in significant fines and legal action. Sometimes, irreversible reputational harm, too.
The British Airways incident is a memorable example.
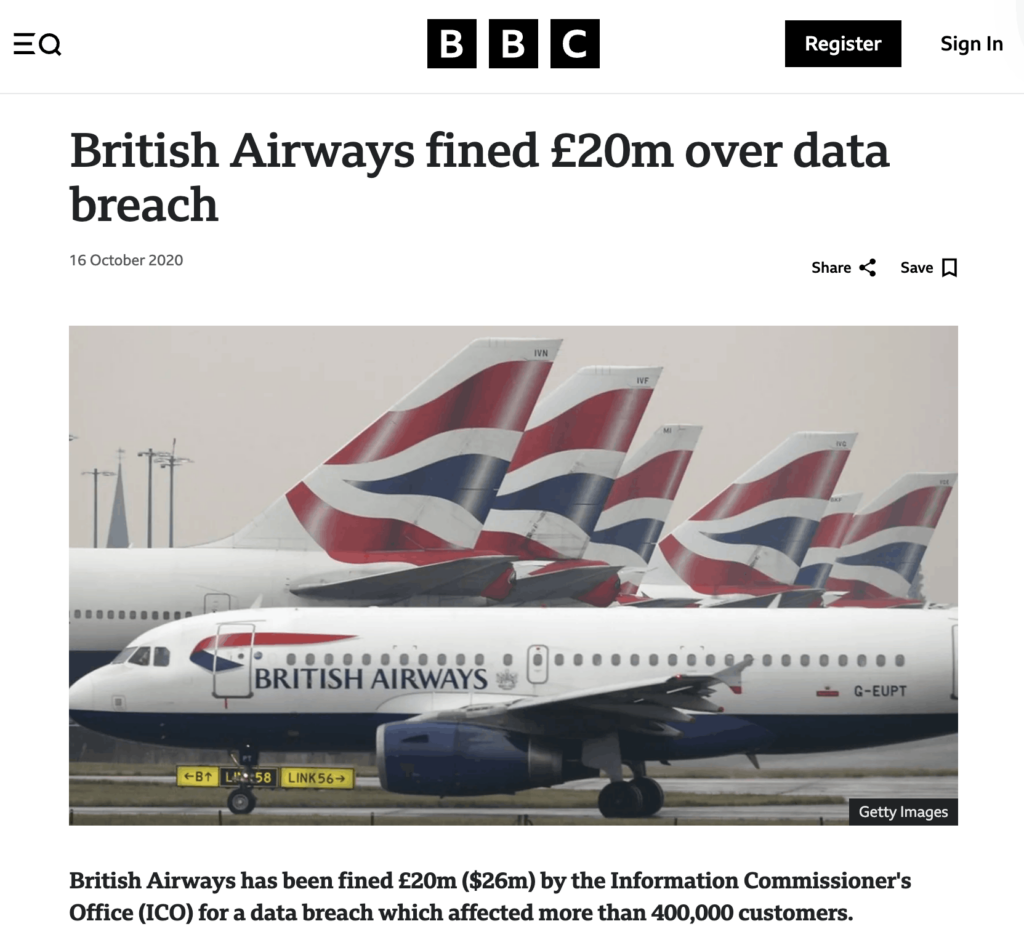
Source: BBC
After a 2018 cyberattack exposed the personal and payment data of over 400,000 customers, the UK Information Commissioner’s Office fined the airline £20 million under GDPR in 2020.
The financial penalty was staggering enough. But the incident triggered intense media scrutiny, too, along with customer backlash, and long-term reputational damage.
Regulators ultimately pointed to insufficient security controls and oversight. In short, a governance failure that let vulnerabilities go undetected.
Speaking of vulnerabilities, common ones often stem from weak access management.
Overprivileged accounts, shared credentials, and inconsistent authentication policies expose sensitive business records unnecessarily.
In large enterprises, employees might accumulate system access over time without periodic review, which further expands internal risk surfaces.
Third-party integrations also amplify exposure if vendor access controls are poorly monitored.
Below are the most common vulnerabilities in business data environments:
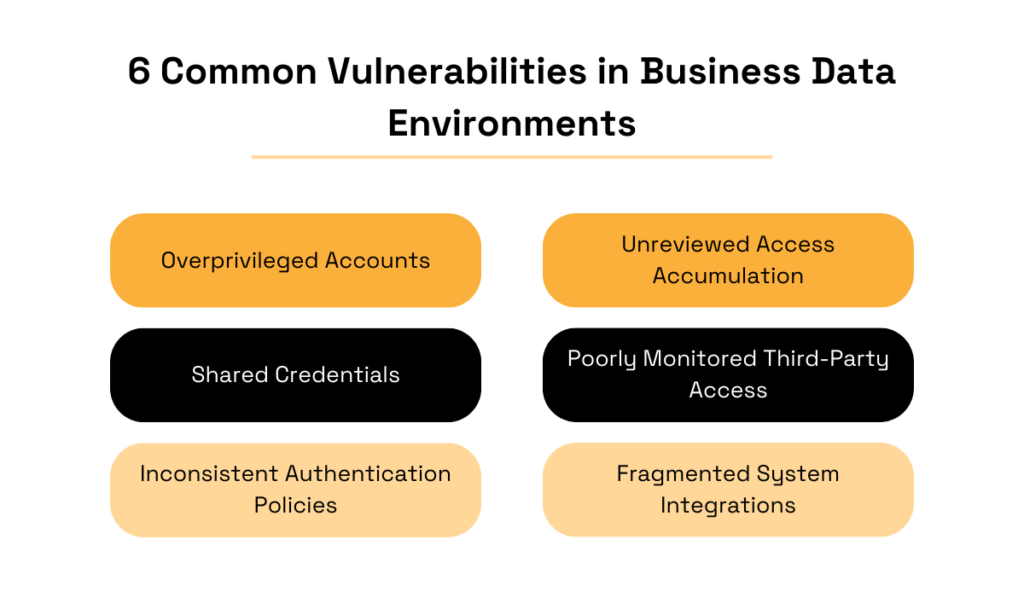
Source: Veridion
Best practices tend to start with role-based access control (RBAC).
Meaning employees should only access the data required for their function, aligned with the principle of least privilege.
Procurement teams may need supplier capability data and just that. Compliance teams only need regulatory documentation. Access should reflect responsibility, not convenience.
Encryption is equally critical.
Protecting business data requires layered security controls across systems and integrations alike:
| Encryption at rest and in transit | Protects sensitive data across storage and transfers |
| Secure API authentication | Ensures trusted system-to-system communication |
| Multi-factor authentication | A critical layer beyond passwords |
| Regular penetration testing | Identifies vulnerabilities before attackers do |
Strengthening data security means every layer should be in perfect sync, from governance policies to technical safeguards and regulatory obligations.
When access is controlled, data is encrypted, and compliance requirements are enforced, business data remains both usable and protected. And that means smarter, less risky decisions.
Business data doesn’t stay accurate just because you cleaned it once. In B2B environments, unfortunately, data decay is a constant affair.
Companies relocate, change leadership, restructure legal entities, expand into new markets, or discontinue product lines entirely.
In fact, Gartner reports that B2B contact data decays at 70.3% per year.
Additionally, Validity reports that 44% of the companies suffer annual revenue losses of over 10% because of CRM data decay.
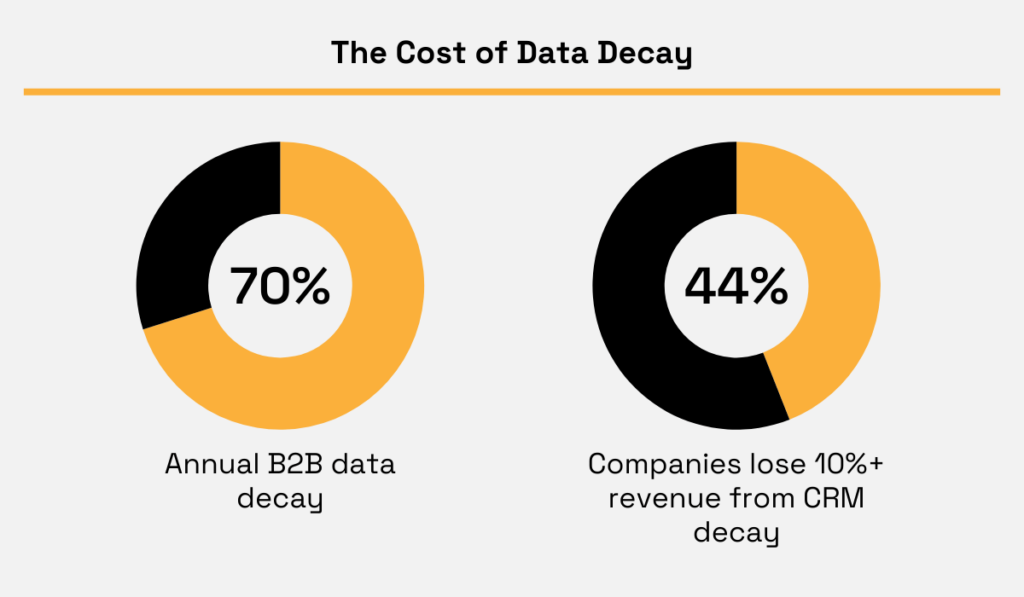
Illustration: Veridion / Data: Gartner & Validity
For large enterprises managing thousands of suppliers or counterparties, even the tiniest inaccuracies add up fast.
And let us drive this point home: one-time cleanup initiatives create temporary improvement but fail to address the way business ecosystems evolve continuously.
If enrichment is not ongoing, normalized and centralized datasets gradually drift out of alignment with the real world.
That drift undermines many layers:
Continuous enrichment addresses this by augmenting internal records with reliable external intelligence.
So rather than relying on self-reported supplier updates or periodic audits, you can validate firmographic, geographic, and operational data against trusted external sources.
Your safest bet here is specialized business data providers that maintain structured, continuously updated company-level intelligence.
This includes:
Continuous enrichment replaces lags with automation. This is where platforms like Veridion can really level it up.
Through Search and Match & Enrich API integrations, external intelligence feeds directly into your master data environment.
That’s where AI models match, validate, and update supplier records in real time.
So you’re skipping manually reconciling spreadsheets or chasing confirmations, and letting your systems flag material changes automatically.
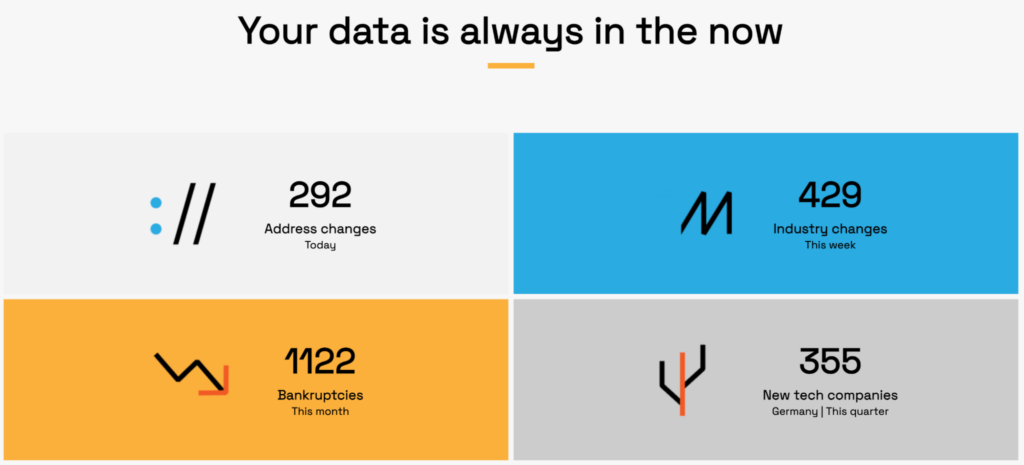
Source: Veridion
Veridion does all this by scanning hundreds of billions of web pages in real time, and by keeping structured profiles for over 123 million suppliers across 246 countries.
That’s how it delivers continuously refreshed, company-level intelligence into your ERP, procurement, or risk systems.
The result is 99%+ deduplication accuracy, enriched supplier attributes, and a synchronized view of corporate hierarchies, products, financial indicators, and ESG signals.

Source: Veridion
In practice, that means no more waiting for quarterly audits to discover duplicates or blindly trusting vendor-submitted forms.
At the end of the day, you’re eliminating the blind spots between ownership changes and compliance reviews.
Continuous enrichment can turn your business data into a live intelligence layer, one that evolves at the same speed as the market.
And that, of course, keeps your decisions grounded in reality.
You’re now ready to take managing business data to the next level.
When your data is standardized, unified, protected, and constantly refreshed, every department is in sync, and every employee makes clearer, more confident decisions.
We live in times of increased complexities and accelerating change. Disciplined data management is thus a must.
Build the right foundation now, and your data will be the engine for smarter, more resilient growth.