- 43% of COOs rank poor data as a top priority and look at data enrichment to fix missing fields.
- Enriched data turns rough categories into predictive groups for sharper segmentation.
- Built from existing data, derived attributes like risk scores drive key decisions.
- 67% don’t trust their data; consistent data categorization creates a shared vocabulary.
Unfortunately, most organizations collect data constantly, but still struggle to do anything useful with it.
That’s because, despite large volumes of information, their records are full of inefficiencies and errors.
Data is missing, hasn’t been updated for years, or repeats throughout the database, but in a slightly different format. All of this makes it unusable.
Luckily, data enrichment addresses this.
It takes what you have and makes it actually work for the decisions you need to make.
Let’s see how.
Appending Data
Raw internal data is almost always incomplete.
A CRM record might hold a company name, a domain, and an industry tag.
But it won’t tell you how fast the company is growing, whether they use the technology your product integrates with, or how many locations they operate across.
That is where data appending comes in.
Appending means pulling attributes from external sources and writing them directly onto existing records.
The goal is a fuller picture of an entity, whether that’s a customer, a prospect, or a supplier, without asking them for more information.
And the stakes are real.
A study by IBM found that 43% of chief operations officers rank data quality issues as their most significant data priority.
And, over a quarter of organizations estimate they lose more than $5 million annually to poor data quality, most of it traceable to records that were never enriched with the attributes needed to make accurate decisions.

This does not have to be the case for your business. You just need to combine your internal sources of information with external ones.
One option worth considering is Veridion.
Powered by AI, Veridion provides comprehensive intelligence on more than 135 million businesses worldwide.
Covering 250+ countries, the platform delivers 320+ data points ranging from firmographic and technographic information to ESG metrics, corporate relationships, product offerings, and geographic insights.

Source: Veridion
The data is refreshed weekly using a custom pipeline built on primary sources like company websites, legal registries, job postings, and news, all validated to over 95% accuracy.
Also, most of the companies you care about, especially SMBs, simply don’t show up in traditional databases. Or, your CRM might just know a company’s name and domain.
Veridion can tell you their revenue range, where they operate, what technologies they use, and whether they meet your ESG criteria.

Source: Veridion
That internal data and external intelligence working together is what drives smarter targeting and more defensible risk decisions.
The best part?
Veridion also integrates with MDM, ERP, SRM, and analytics platforms via a robust API, so no rebuild is required.
Segmentation
Put simply, data segmentation involves dividing a data object, such as a customer, product, or location, into groups based on a common set of pre-defined variables, such as age, gender, or income.
Spotify does this very well.
According to a Pragmatic Institute case study, Spotify uses collaborative filtering, NLP, and audio analysis models to enrich listener profiles continuously and build an evolving audio identity for each user.
Source: MarTech360
That enriched profile powers Discover Weekly, Daily Mixes, and Release Radar. The result: 751 million monthly active users by Q4 2025, with personalization as a stated primary driver of retention.
B2B teams apply the same logic at the account level, except the signal is firmographic, not behavioral. Without enrichment, these teams are dividing prospects by industry and company size, and that’s roughly it.
But with enriched data, they can layer in revenue range, technology stack, hiring signals, geographic footprint, and growth trajectory.
The same logic applies in e-commerce.
A fashion retailer enriching customer records with behavioral data and purchase history can separate occasional buyers from brand loyalists, then again by category preference, average order value, and seasonal patterns.
In finance, when revenue range, headcount trajectory, technology stack, and recent funding activity are appended to a CRM, even a flat list of 5,000 prospects becomes tiered.
Derived Attributes
A derived attribute is any field you calculate or construct from existing data rather than collect directly.
A customer’s lifetime value. A supplier’s risk score. A prospect’s estimated buying readiness.
None of these exist in a form you can simply pull from a database. You have to build them from the data you already have.
The simplest example?
‘Age’ being derived based on a ‘date of birth’ field.
American Express has been using derived attributes for fraud prevention long before AI-driven risk scoring became mainstream.

Source: American Express Newsroom
Instead of relying solely on transaction details like purchase amount or card number, the company combines existing data points such as spending patterns, merchant information, shipping addresses, email IDs, and IP addresses to generate fraud risk scores in real time.
These calculated attributes help determine whether a transaction matches a cardholder’s usual behavior or signals potential fraud.
However, when it comes to derived attributes, the trap is volume over precision.
Automated tools can generate thousands of candidate features from any dataset. Domain expertise is what separates a useful derived attribute from statistical text.
And the question to answer before building any derived field is: what decision will this actually support?
Data Manipulation
Here’s something that gets overlooked in most data enrichment conversations: the raw material matters, but so does what you do to it before you use it.
Manipulation is the step where raw and appended data get transformed into something systems can actually use together, involving:
- Normalization
- Aggregation
- Deduplication
- Reformatting
…all before anything analytical happens.
A company listed as ‘XYZ Corp,’ ‘XYZ Corporation,’ and ‘XYZ Corp Ltd.’ in three different systems is actually one entity, but your tools won’t know that until the names are standardized.
The same applies to date formats, revenue fields stored in different currencies, phone numbers without country codes, and country names abbreviated differently across databases.
Now, data manipulation is not glamorous work, but it’s what keeps enrichment from going sideways.
Uber AI Solutions provides a compelling example of how intelligent data manipulation can significantly improve outcomes.
As demand for high-quality labeled datasets grew across industries, Uber faced a common challenge: identifying labeling errors early without relying heavily on time-consuming post-review audits.
To address this, Uber developed an LLM-powered framework called Requirement Adherence, embedded directly into its annotation platform, uLabel.

Source: Uber Blog
Instead of treating client instructions as static documents, the system transformed them into structured, machine-readable rules.
These rules were categorized based on complexity, from straightforward formatting checks to nuanced, context-driven requirements, and applied in real time as annotations were created.
This approach fundamentally changed how annotation quality was managed.
Rather than correcting errors after submission, Uber manipulated and standardized incoming instruction data to provide instant feedback and improvement suggestions to labelers.
The business impact was substantial. Uber reported an 80% reduction in manual audits, enabling faster project completion, lower operational costs, and more reliable datasets.
What manipulation is really about is making data from different origins compatible with each other.
When done well, everything downstream, right enrichment, segmentation, and modeling works from a foundation that holds.
Entity Extraction
A surprising amount of business intelligence is buried in text.
It lives in contracts, regulatory filings, supplier communications, news articles, and even job postings.
All of it unstructured, all of it full of names, dates, relationships, financial figures, and risk signals that would be genuinely valuable if they could be pulled out reliably.
Entity extraction makes that possible.
It identifies and classifies specific elements within unstructured text: organization names, people, locations, monetary values, product references, and dates, and converts prose into structured, queryable data.
Take the case of JPMorgan.
JPMorgan’s COiN (Contract Intelligence) platform uses NLP to automatically extract over 150 attributes from commercial loan agreements: clause types, payment terms, covenant language, counterparty names, obligation dates, and collateral details.
What previously required 360,000 hours of manual review annually is now processed in seconds, across 12,000 commercial credit agreements per year!

Source: Harvard Business School
For procurement and supply chain teams, entity extraction from news feeds and regulatory filings catches risk signals early.
- A supplier mentioned in a sanctions update
- A logistics partner flagged in a financial filing
- A manufacturer appearing in a negative press cluster
These signals exist in text long before they show up in any structured database.
But here is an important thing to remember: entity extraction is only as good as the model’s training data and the clarity of the source text.
Ambiguous language, domain-specific jargon, and inconsistent formatting all create classification errors, which we discuss in detail below.
Categorization
Data categorization is the process of assigning records, companies, products, transactions, or any other entity to a structured, agreed-upon set of categories.
It basically helps create a shared vocabulary that makes data comparable across systems, teams, and time.
But the absence of it creates more downstream problems than most organizations realize.
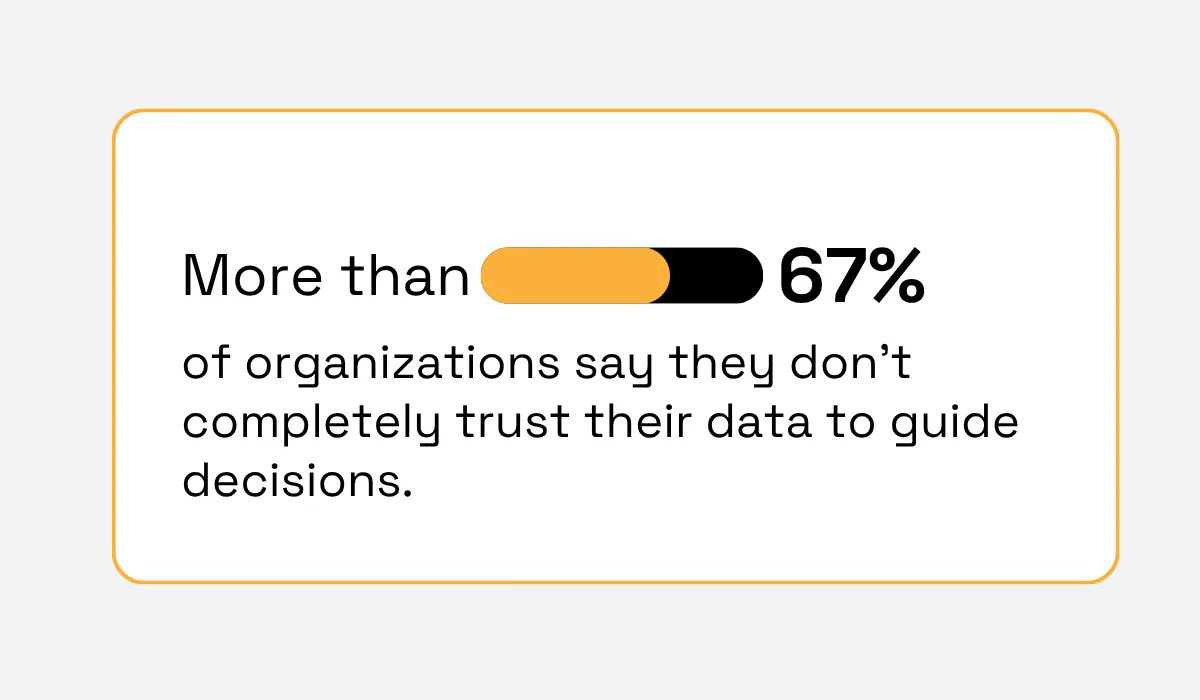
A 2025 Planning Insights Report cited by Precisely found that 67% of organizations say they don’t completely trust their data to guide decisions. A big part of that distrust comes from inconsistent or absent categorization.
But on the flip side, when data categorization is done with due care, it can fundamentally change how businesses operate.
Walmart is an excellent example here.
The company improved product discovery across its catalog of 400+ million SKUs by strengthening how products were categorized and linked to the right product types.
Using its AI-powered system, Ghotok, Walmart combined predictive and generative AI to identify accurate relationships between categories and products, reducing data misclassification at scale.
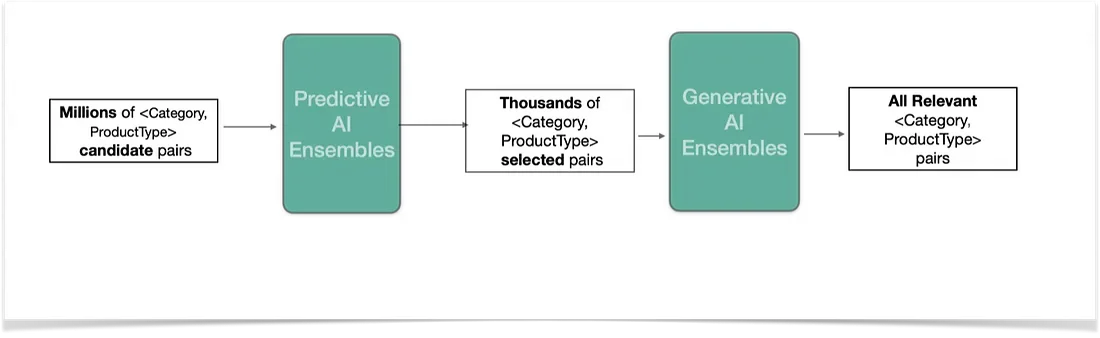
Source: Walmart Global Tech Blog
This helped surface more relevant products to shoppers, improved search precision, and created a smoother online shopping experience while efficiently managing millions of catalog relationships.
Conclusion
Data enrichment is not a one-time project
Appending external data, building smarter segments, deriving meaningful attributes, normalizing through manipulation, extracting entities from text, and maintaining consistent categorization–each solves a specific problem.
Together, they turn an incomplete dataset into something a business can actually build on.
The organizations that get this right spend less time correcting data errors and more time acting on real insight. That efficiency gain compounds across every decision.
Start with the technique most relevant to your current gaps, and build from there.
Articles
Discuss how these trends affect your organization.
Our analysts are available for a short call. Bring a specific question and we will ground it in the data.